보도 자료 요약
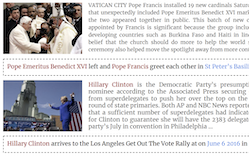
메릴랜드 대학교, 버지니아 대학교, 라이스 대학교의 연구자들은 The Guardian, BBC, USA Today, The Washington Post의 네 매체에서 추출한 기사 텍스트, 캡션, 메타데이터와 짝지어진 백만 개 이상의 뉴스 이미지로 구성된 데이터셋인 Visual News를 공개했으며, 이는 그 종류 중 현재까지 가장 큰 모음이다. 이 연구는 이미지 캡셔닝 연구의 실질적인 격차를 다룬다: Microsoft COCO 같은 기존 데이터셋은 "빨간 우산을 들고 있는 한 무리의 사람들"과 같은 일반적인 설명을 생성하도록 모델을 학습시키는데, 이는 뉴스 사진을 의미 있게 만드는 누가, 어디서, 무엇을 포착하지 못한다. 데이터셋을 활용하기 위해, 연구팀은 또한 이미지와 함께 제공되는 기사 텍스트 모두에서 정보를 끌어내어 모호한 자리표시자가 아닌 특정 명명된 개체(사람, 장소, 조직)를 포함하는 캡션을 생성하는 Transformer 기반 모델인 Visual News Captioner를 구축했다. 이 모델은 "Attention on Attention" 메커니즘, 인코딩 중 이미지와 텍스트 특징을 연결하는 Visual Selective Layer, 그리고 모델 어휘 밖에 있는 드문 단어를 처리하는 Tag-Cleaning 단계를 포함한 여러 기술적 추가 요소를 도입한다. 세 개의 데이터셋에서 경쟁 접근법과 비교 테스트한 결과, Visual News Captioner는 가장 가까운 경쟁자의 약 절반에 해당하는 파라미터 수를 사용하면서도 표준 캡셔닝 지표에서 최첨단 기술과 동등하거나 이를 능가했다. 연구자들은 또한 한 뉴스 통신사의 데이터로 학습된 모델이 다른 통신사의 콘텐츠로 테스트되었을 때 눈에 띄게 더 나쁘게 수행됨을 발견했는데, 이는 작문 스타일과 편집 초점이 뉴스룸마다 얼마나 다양한지, 그리고 진정으로 다양한 환경에서 이 문제가 얼마나 더 어려워지는지를 강조한다.
초록
우리는 뉴스 이미지 캡셔닝 작업을 위한 개체 인식(entity-aware) 모델인 Visual News Captioner를 제안한다. 우리는 또한 백만 개 이상의 뉴스 이미지와 관련 뉴스 기사, 이미지 캡션, 저자 정보 및 기타 메타데이터로 구성된 대규모 벤치마크인 Visual News를 도입한다. 표준 이미지 캡셔닝 작업과 달리, 뉴스 이미지는 사람, 장소, 사건이 가장 중요한 상황을 묘사한다. 우리가 제안하는 방법은 시각적 특징과 텍스트 특징을 효과적으로 결합하여 사건과 개체 같은 더 풍부한 정보를 담은 캡션을 생성할 수 있다. 더 구체적으로, Transformer 아키텍처 위에 구축된 우리 모델은 명명된 개체(named entity)를 더 정확하게 생성하도록 설계된 새로운 멀티모달 특징 융합 기법과 attention 메커니즘을 추가로 갖추고 있다. 우리의 방법은 경쟁 방법보다 훨씬 적은 파라미터를 사용하면서도 약간 더 나은 예측 결과를 달성한다. 우리의 더 크고 더 다양한 Visual News 데이터셋은 뉴스 이미지 캡셔닝에 남아 있는 과제를 한층 더 부각시킨다.
세부 정보
인용
@inproceedings{liu2021visualnews,
title = {VisualNews : Benchmark and Challenges in Entity-aware Image Captioning},
author = {Liu, Fuxiao and Wang, Yinghan and Wang, Tianlu and Ordonez, Vicente},
year = {2021},
booktitle = {Empirical Methods in Natural Language Processing. EMNLP 2021},
url = {https://arxiv.org/abs/2010.03743},
}