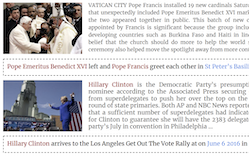
新闻稿摘要
来自马里兰大学、弗吉尼亚大学和莱斯大学的研究人员发布了 Visual News,一个包含超过一百万张新闻图像、配以文章文本、描述和元数据的数据集,取自四家媒体——The Guardian、BBC、USA Today 和 The Washington Post——使其成为迄今同类中最大的集合。这项工作填补了图像描述研究中的一个真实缺口:像 Microsoft COCO 这样的现有数据集训练模型生成诸如“一群人举着红伞”之类的通用描述,无法捕捉使新闻照片有意义的“谁、在哪里、发生了什么”。为了应用该数据集,团队还构建了 Visual News Captioner,一个基于 Transformer 的模型,它从图像和随附的文章文本中提取信息,生成包含具体命名实体——人物、地点和组织——的描述,而非含糊的占位词。该模型引入了若干技术补充,包括“Attention on Attention”机制、在编码期间链接图像和文本特征的 Visual Selective Layer,以及用于处理超出模型词汇表的罕见词的 Tag-Cleaning 步骤。在三个数据集上与竞争方法对比测试中,Visual News Captioner 在标准描述指标上匹敌或超越了现有最优水平,同时使用的参数量大约只有其最接近对手的一半。研究人员还发现,在一家新闻机构数据上训练的模型,在另一家机构的内容上测试时表现明显更差,这凸显了不同新闻编辑室之间写作风格和编辑重点的差异之大——以及在真正多样化的环境中这一问题会变得多么困难。
摘要
我们提出 Visual News Captioner,一个面向新闻图像描述任务的实体感知模型。我们还引入了 Visual News,一个由超过一百万张新闻图像及其相关新闻文章、图像描述、作者信息和其他元数据组成的大规模基准。与标准图像描述任务不同,新闻图像描绘的是人物、地点和事件至关重要的情境。我们提出的方法能够有效结合视觉和文本特征,生成包含事件和实体等更丰富信息的描述。更具体地说,我们的模型构建在 Transformer 架构之上,并进一步配备了新颖的多模态特征融合技术和注意力机制,旨在更准确地生成命名实体。我们的方法使用更少的参数,同时取得了略优于竞争方法的预测结果。我们更大、更多样化的 Visual News 数据集进一步凸显了为新闻图像生成描述所面临的剩余挑战。
详情
引用
@inproceedings{liu2021visualnews,
title = {VisualNews : Benchmark and Challenges in Entity-aware Image Captioning},
author = {Liu, Fuxiao and Wang, Yinghan and Wang, Tianlu and Ordonez, Vicente},
year = {2021},
booktitle = {Empirical Methods in Natural Language Processing. EMNLP 2021},
url = {https://arxiv.org/abs/2010.03743},
}