Testing DNN Image Classifiers for Confusion & Bias Errors
Zusammenfassung der Pressemitteilung
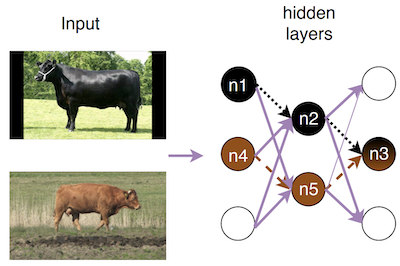
Forscher der Columbia University und der University of Virginia haben ein Testwerkzeug namens DeepInspect entwickelt, das automatisch nach systematischen Fehlern in den tiefen neuronalen Netzen sucht, die zur Klassifikation von Bildern verwendet werden — die Art von Software hinter allem von Google Photos bis zu medizinischen Diagnosesystemen. Das Team war motiviert durch eine Klasse von Fehlern, die über einmalige Irrtümer hinausgehen: Fälle, in denen ein Modell eine ganze Bildkategorie konsequent mit einer anderen verwechselt oder zwei Gruppen von Menschen ungleich behandelt — Probleme, die sie als "Verwechslungs-" und "Verzerrungsfehler" bezeichnen. Anstatt einzelne Bilder zu untersuchen, wie es die meisten bestehenden Testmethoden tun, funktioniert DeepInspect, indem es verfolgt, welche Neuronen innerhalb eines Netzes feuern, wenn das Modell jede Bildklasse verarbeitet, und dann ein statistisches Profil dieser Aktivierungsmuster pro Klasse erstellt. Wenn zwei Klassen verdächtig ähnliche Mengen von Neuronen aktivieren, kennzeichnet das Werkzeug sie als wahrscheinlich verwechselt; wenn das Modell unterschiedliche Abstände zwischen etwa "man" und "surfboard" gegenüber "woman" und "surfboard" beibehält, kennzeichnet es diese Asymmetrie als potenzielle Verzerrung. Getestet über acht neuronale Netzmodelle und sechs bekannte Datensätze hinweg — darunter ImageNet, COCO und CIFAR — fand das Werkzeug Hunderte echter Klassifikationsfehler und erkannte Verwechslungsfehler mit einer Präzision von bis zu 100 Prozent und Verzerrungsfehler mit einer Präzision von bis zu 84 Prozent, wenn es sich auf seine bestplatzierten Befunde konzentrierte. Bemerkenswerterweise deckte es diese Mängel auf Klassenebene sogar in Modellen auf, die speziell darauf ausgelegt waren, robust gegenüber adversarialen Angriffen zu sein, was darauf hindeutet, dass die beiden Problemtypen weitgehend unabhängig voneinander sind. Die Arbeit ist bedeutsam, weil Fehler auf Klassenebene im Gegensatz zu isolierten Fehlvorhersagen strukturelle Schwächen darstellen, die ganze Gruppen von Nutzern oder Objekten betreffen — die Art von Mangel, die zu Googles berüchtigtem Vorfall von 2015 führte, bei dem Fotos schwarzer Menschen als Gorillas getaggt wurden — und bestehende Test-Frameworks übersehen sie weitgehend.
Zusammenfassung
Bildklassifikatoren sind ein wichtiger Bestandteil heutiger Software, von Verbraucher- und Geschäftsanwendungen bis hin zu sicherheitskritischen Bereichen. Das Aufkommen von Deep Neural Networks (DNNs) ist der zentrale Katalysator hinter einem derart weitverbreiteten Erfolg. Die breite Akzeptanz geht jedoch mit ernsthaften Bedenken hinsichtlich der Robustheit von Softwaresystemen einher, die für die Bildklassifikation auf DNNs angewiesen sind, da unter sensiblen und kritischen Umständen mehrere schwerwiegende Fehlverhalten berichtet wurden. Wir argumentieren, dass Entwickler die Bildklassifikatoren ihrer Software rigoros testen und die Bereitstellung verzögern müssen, bis sie akzeptabel ist. Wir präsentieren einen Ansatz zum Testen der Robustheit von Bildklassifikatoren auf der Grundlage von Verletzungen von Klasseneigenschaften. Wir stellten fest, dass viele der berichteten Fehlerfälle in populären DNN-Bildklassifikatoren auftreten, weil die trainierten Modelle eine Klasse mit einer anderen verwechseln oder Verzerrungen zugunsten bestimmter Klassen gegenüber anderen aufweisen. Diese Fehler verletzen in der Regel einige Klasseneigenschaften einer oder mehrerer dieser Klassen. Die meisten Techniken zum Testen von DNNs konzentrieren sich auf Verletzungen pro Bild und versagen daher dabei, Verwechslungen oder Verzerrungen auf Klassenebene zu erkennen. Wir entwickelten eine Testtechnik zur automatischen Erkennung von klassenbasierten Verwechslungs- und Verzerrungsfehlern in DNN-gestützter Bildklassifikationssoftware. Wir evaluierten unsere Implementierung, DeepInspect, auf mehreren populären Bildklassifikatoren mit einer Präzision von bis zu 100% (Durchschnitt ~72,6%) für Verwechslungsfehler und bis zu 84,3% (Durchschnitt ~66,8%) für Verzerrungsfehler. DeepInspect fand Hunderte von Klassifikationsfehlern in weit verbreiteten Modellen, von denen viele Fehler aufdeckten, die auf Verwechslung oder Verzerrung hindeuten.
Details
Zitation
@inproceedings{tian2020testing,
title = {Testing DNN Image Classifiers for Confusion & Bias Errors},
author = {Tian, Yuchi and Zhong, Ziyuan and Ordonez, Vicente and Kaiser, Gail and Ray, Baishakhi},
year = {2020},
booktitle = {International Conference on Software Engineering. ICSE 2020},
url = {https://arxiv.org/abs/1905.07831},
}