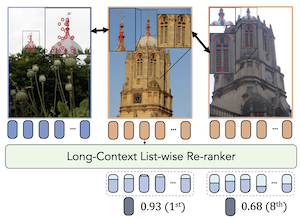
LoCoRe: Image Re-ranking with Long-Context Sequence Modeling
Zusammenfassung der Pressemitteilung
Forschende der Rice University und der Tschechischen Technischen Universität in Prag haben ein neues Bild-Retrieval-System namens LOCORE entwickelt, das überdenkt, wie Suchmaschinen nach einer ersten breiten Suche Kandidatenbilder eingrenzen und neu ranken. Traditionelle Re-Ranking-Systeme vergleichen ein Anfragebild mit jedem Kandidatenbild einzeln, jeweils ein Paar nach dem anderen, was bedeutet, dass sie nützliche Beziehungen zwischen den Kandidatenbildern selbst übersehen — etwa die Tatsache, dass zwei Galeriebilder Merkmale gemeinsam haben könnten, die zusammen einen stärkeren Hinweis auf eine Übereinstimmung liefern. LOCORE verarbeitet stattdessen die Anfrage zusammen mit einer ganzen Auswahlliste von bis zu 100 Kandidatenbildern gleichzeitig und verwendet dabei ein Long-Context-Transformer-Modell namens Longformer, das ursprünglich für lange Textdokumente entwickelt wurde, um diese bildübergreifenden Abhängigkeiten auf der Ebene feinkörniger lokaler visueller Deskriptoren zu erfassen. Um Situationen zu bewältigen, in denen die Auswahlliste das überschreitet, was das Modell auf einmal im Speicher halten kann, entwarf das Team eine Sliding-Window-Strategie, die sich in überlappenden Abschnitten durch die Kandidatenliste bewegt. In Tests über fünf Benchmark-Datensätze hinweg, die Sehenswürdigkeiten, Produkte, Modeartikel und Vogelarten abdecken, übertraf LOCORE durchgängig bestehende Re-Ranking-Methoden, einschließlich paarweiser Ansätze mit lokalen Deskriptoren und listenweiser Ansätze mit globalen Deskriptoren, während es bei vergleichbarer oder geringerer Latenz lief und deutlich weniger Speicher verbrauchte. Die Arbeit ist von Bedeutung, weil ein besseres Re-Ranking die Genauigkeit von Bildsuchsystemen direkt verbessert, und der Ansatz zeigt, dass Ideen aus der Verarbeitung natürlicher Sprache — insbesondere Long-Context-Modellierung und Klassifikation auf Token-Ebene — wirksam auf visuelle Retrieval-Aufgaben übertragen werden können.
Zusammenfassung
Wir stellen LOCORE, Long-Context Re-ranker, vor, ein Modell, das lokale Deskriptoren entsprechend einer Bildanfrage und einer Liste von Galeriebildern als Eingabe entgegennimmt und Ähnlichkeitswerte zwischen der Anfrage und jedem Galeriebild ausgibt. Dieses Modell wird für das Bild-Retrieval verwendet, bei dem typischerweise zunächst ein Ranking mit einem effizienten Ähnlichkeitsmaß durchgeführt wird und anschließend eine Auswahlliste der am höchsten gerankten Bilder auf Basis eines feinkörnigeren Ähnlichkeitsmaßes neu gerankt wird. Im Vergleich zu bestehenden Methoden, die eine paarweise Ähnlichkeitsschätzung mit lokalen Deskriptoren oder ein listenweises Re-Ranking mit globalen Deskriptoren durchführen, ist LOCORE die erste Methode, die ein listenweises Re-Ranking mit lokalen Deskriptoren durchführt. Um dies zu erreichen, nutzen wir effiziente Long-Context-Sequenzmodelle, um die Abhängigkeiten zwischen Anfrage- und Galeriebildern auf der Ebene lokaler Deskriptoren wirksam zu erfassen. Beim Testen verarbeiten wir lange Auswahllisten mit einer Sliding-Window-Strategie, die darauf zugeschnitten ist, die Begrenzungen der Kontextgröße von Sequenzmodellen zu überwinden. Unser Ansatz erzielt eine überlegene Leistung im Vergleich zu anderen Re-Rankern auf etablierten Bild-Retrieval-Benchmarks für Sehenswürdigkeiten (ROxf und RPar), Produkte (SOP), Modeartikel (In-Shop) und Vogelarten (CUB-200), während er eine vergleichbare Latenz zu den paarweisen Re-Rankern mit lokalen Deskriptoren aufweist.
Details
Zitation
@inproceedings{xiao2025locore,
title = {LoCoRe: Image Re-ranking with Long-Context Sequence Modeling},
author = {Xiao, Zilin and Suma, Pavel and Sachdeva, Ayush and Wang, Hao-Jen and Kordopatis-Zilos, Giorgos and Tolias, Giorgos and Ordonez, Vicente},
year = {2025},
booktitle = {Conf. on Computer Vision and Pattern Recognition. CVPR 2025},
url = {https://arxiv.org/abs/2503.21772},
}
automatisch generierte Fragen, wichtigste Beiträge und Grenzen dieses Artikels
Fragen, die dieser Artikel beantworten hilft
- Was ist LOCORE und welches Problem adressiert es? LOCORE ist ein Long-Context-Modell zum Bild-Re-Ranking, das ein Anfragebild und eine Auswahlliste von Galeriebildern gemeinsam mithilfe lokaler Deskriptoren verarbeitet und so das in Bild-Retrieval-Systemen verwendete Ranking der zweiten Stufe verbessert.
- Wie unterscheidet sich LOCORE von paarweisen Re-Rankern? Paarweise Methoden vergleichen die Anfrage unabhängig mit jedem Galeriebild, während LOCORE die gesamte Auswahlliste gemeinsam modelliert, sodass es sowohl Beziehungen zwischen Galeriebildern als auch Anfrage-Galerie-Übereinstimmungen ausnutzen kann.
- Warum verwendet LOCORE ein Long-Context-Sequenzmodell? Das Re-Ranking von bis zu 100 Galeriebildern mit lokalen Deskriptoren erzeugt eine lange Token-Sequenz, und Attention im Longformer-Stil ermöglicht es dem Modell, nützliche Abhängigkeiten mit handhabbarem Speicher und handhabbarer Latenz zu erfassen.
- Wie geht LOCORE mit Auswahllisten um, die länger als sein Kontextfenster sind? Es verwendet eine überlappende Sliding-Window-Strategie, die den listenweisen Re-Ranker über Teile der Auswahlliste hinweg wiederverwendet, was es der Methode erlaubt, Rankings über die maximale in einem Forward-Pass gesehene Listengröße hinaus zu verbessern.
- Welche Retrieval-Benchmarks verbessert LOCORE? Die Arbeit berichtet über führende oder dem Stand der Technik entsprechende Re-Ranking-Ergebnisse bei Retrieval-Benchmarks für Sehenswürdigkeiten, Produkte, Mode und Vogelarten, einschließlich ROxf/RPar, SOP, In-Shop und CUB-200.
Wichtigste Beiträge
- Die Arbeit führt das erste Framework für listenweises Bild-Re-Ranking ein, das auf der Ebene lokaler Deskriptoren arbeitet, statt sich auf paarweises lokales Matching oder listenweise globale Deskriptoren zu stützen.
- LOCORE formuliert das Bild-Re-Ranking als ein Long-Context-Klassifikationsproblem auf Token-Ebene neu und überträgt dabei Ideen aus der NLP-Span-Extraktion und dem Sequenz-Tagging auf das visuelle Retrieval.
- Das Modell verwendet globale Attention für die Anfrage, Trenn-Token und gemischtes Galerie-Training, um Positions-Shortcuts zu vermeiden und bedeutungsvolle bildübergreifende Deskriptor-Interaktionen zu lernen.
- Über ROxf/RPar und ihre Varianten mit 1 Mio. Distraktoren hinweg verbessert sich LOCORE gegenüber früheren Re-Rankern mit lokalen Deskriptoren wie geometrischer Verifikation, RRT, CVNet und AMES bei vergleichbaren Deskriptor-Einstellungen.
- Die Methode verbessert außerdem Metric-Learning-Retrieval-Benchmarks wie CUB-200, SOP und In-Shop und zeigt damit, dass listenweises Re-Ranking mit lokalen Deskriptoren auch über das Sehenswürdigkeiten-Retrieval hinaus nützlich ist.
Grenzen und Vorbehalte
- LOCORE ist ein Re-Ranker der zweiten Stufe und kein Ersatz für ein effizientes Retrieval der ersten Stufe, was für groß angelegte Such-Pipelines angemessen ist, in denen ein kompakter globaler Deskriptor zunächst die Kandidatenliste eingrenzt.
- Die Methode hängt von hochwertigen lokalen Deskriptoren aus Systemen wie DELG oder DINOv2 ab, was sie jedoch zu einer Ergänzung von Fortschritten bei der Extraktion lokaler Merkmale macht, statt sie an ein einziges Backbone zu binden.
- Die Long-Context-Verarbeitung hat ein endliches Kontextfenster, sodass sehr lange Auswahllisten eine Sliding-Window-Inferenz erfordern; die Arbeit zeigt, dass diese Strategie gut funktioniert und die Vorteile über die Listengröße im Training hinaus erweitern kann.
- Das Training erfordert Sorgfalt, um Positions-Shortcuts aus dem anfänglichen globalen Ranking zu vermeiden, aber gemischtes Galerie-Training ist eine einfache und effektive Lösung, die in den Ablationen demonstriert wird.
- Die Bewertung konzentriert sich auf etablierte Retrieval-Benchmarks auf Instanzebene und lässt breitere produktive Such-Szenarien und domänenspezifische Bildsammlungen als natürliche nächste Deployment-Studien offen.
Wie dieses Ergebnis zu lesen ist
Diese Arbeit lässt sich am besten als ein starker Beitrag zum Re-Ranking beim Bild-Retrieval lesen: LOCORE zeigt, dass eine listenweise Long-Context-Modellierung lokale Deskriptoren leistungsfähiger machen kann, was die Genauigkeit über vielfältige Benchmarks hinweg verbessert und dabei Latenz und Speicher für das Retrieval der zweiten Stufe praktikabel hält.