
소식 및 공지
- 07/2026. Jefferson의 Softmax Advantage Group Estimation (SAGE)에 관한 연구가 COLM 2026에 채택되었습니다.
- 04/2026. Zilin이 박사 학위 논문을 디펜스하고 Meta Superintelligence Labs에서 새로운 직무를 시작합니다~!
- 03/2026. Moayed의 ELIT가 CVPR 2026에 채택되었으며, 올여름 콜로라도주 덴버에서 발표할 예정입니다.
- 01/2026. ICLR 2026에 세 편의 논문이 채택되었습니다. Zilin, Jaywon, Jefferson의 ProxyThinker가 채택되었습니다. Meta Superintelligence Labs와의 협업을 통해 MetaEmbed도 발표하며, Hanjie Chen 그룹이 주도한 스포츠 시각 추론을 위한 새로운 벤치마크 SportR도 발표합니다.
- 09/2025. Moayed의 Decomposable Flow Matching(DFM)에 관한 연구가 NeurIPS 2025에 채택되었습니다 [DFM]
- 09/2025. Jaywon, Jefferson, Moayed의 조건부 Fréchet 거리를 활용한 텍스트-이미지 합성 평가에 관한 연구가 WACV 2026에 채택되었습니다 [cFreD]
- 07/2025. Catherine의 SynGround 논문이 올해 영국 셰필드에서 열리는 British Machine Vision Conference(BMVC)에 채택되었습니다.
- 06/2025. ICCV 2025: Moayed가 AV-Link를, Jefferson이 Panel-of-Peers를 올해 하와이 호놀룰루에서 열리는 ICCV에서 발표합니다!
- 03/2025. Zilin이 체코 공과대학교와 협업한 긴 문맥 이미지 재순위화에 관한 연구가 CVPR 2025에 채택되었습니다 [LoCoRe]
- 09/2024. Jaywon의 코드 어서션과 속성 테스트에 기반한 시각 프로그래밍 향상에 관한 연구가 Findings of EMNLP 2024에 채택되었습니다 [PropTest]
최근 논문
전체 논문 →

Agentic Discovery with Active Hypothesis Exploration for Visual Recognition
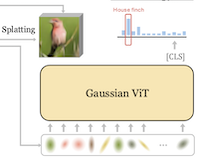
GViT: Representing Images as Gaussians for Visual Recognition
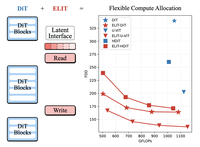
One Model, Many Budgets: Elastic Latent Interfaces for Diffusion Transformers
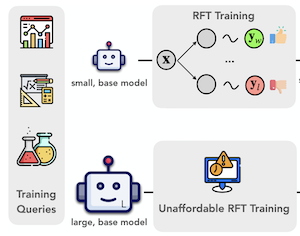
ProxyThinker: Test-Time Guidance through Small Visual Reasoners
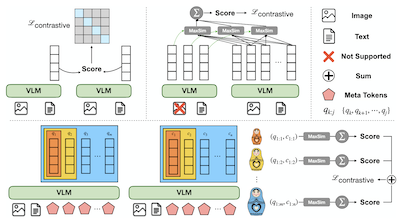
MetaEmbed: Scaling Multimodal Retrieval at Test-Time with Flexible Late Interaction

SportR: A Benchmark for Multimodal Large Language Model Reasoning in Sports
Taming Data and Transformers for Audio Generation

Evaluating Text-to-Image Synthesis with a Conditional Fréchet Distance
현재 및 과거 후원사