新闻稿摘要
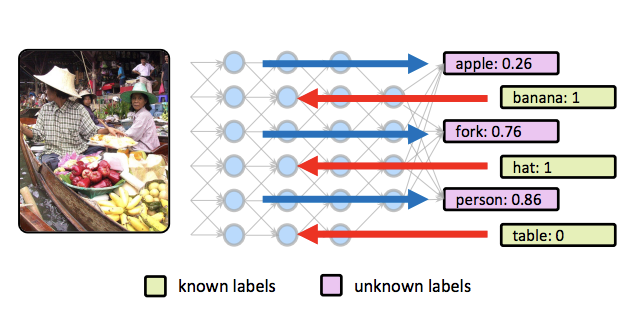
来自弗吉尼亚大学和 CyberAgent 的研究人员开发了一种技术,让现有的图像识别神经网络在关于一张照片的某些信息事先已知时能做出更好的预测。该方法名为 feedback-prop,它弥合了计算机视觉系统通常如何被测试——仅使用视觉输入——与它们实际上常常如何被使用之间的差距,在实际使用中,周围的文本、GPS 数据、用户标签或其他上下文线索往往是可获得的。研究人员发现,与其重新训练网络以纳入这些额外信息,不如在推理步骤本身中将已知标签反馈回一个训练好的网络,调整网络的内部激活,直到对其余未知标签的预测有所改善。他们测试了该方法的两个变体——一个逐层顺序更新,另一个在多个层同时注入小的校正变量——涵盖若干任务,包括在某些标签已知时识别图像中的物体、在给定粗类别时预测细粒度场景类别,以及在物体标注可获得时生成图像字幕。在所有任务和包括 VGG-16 和 ResNet 在内的多种标准网络架构上,加入部分证据都持续提升了准确率,相对增益视任务而定大约在 10% 到 13% 之间。值得注意的是,该技术不需要对原始模型的训练做任何改动,并能与任意已知和未知标签的混合配合工作,这使它在图像很少在没有任何伴随上下文的情况下到达的现实部署场景中具有广泛的实用性。
摘要
我们为深度卷积神经网络(CNN)提出了一种在可获得部分证据时的推理过程。我们的方法由一种通用的基于反馈的传播方法(feedback-prop)构成,当一组互不重叠的目标标签的取值已知时,它能提升对任意一组未知目标标签的预测准确率。我们表明,在多标签或多任务设置下训练得到的现有模型可以直接利用 feedback-prop,而无需任何重新训练或微调。我们的 feedback-prop 推理过程通用、简单、可靠,并能在不同的具有挑战性的视觉识别任务上工作。我们提出了 feedback-prop 的两个变体,分别基于逐层更新和残差迭代更新。我们使用若干多任务模型进行实验,表明 feedback-prop 在它们之中都有效。我们的结果揭示了深度 CNN 一种此前未被报告但有趣的动态性质。我们还提出了一种相关的技术方法,在一般视觉识别任务中利用这一性质进行部分证据下的推理。
详情
引用
@inproceedings{wang2018feedback,
title = {Feedback-prop: Convolutional Neural Network Inference under Partial Evidence},
author = {Wang, Tianlu and Yamaguchi, Kota and Ordonez, Vicente},
year = {2018},
booktitle = {Conference on Computer Vision and Pattern Recognition. CVPR 2018},
url = {https://arxiv.org/abs/1710.08049},
}