General Multi-label Image Classification with Transformers
Zusammenfassung der Pressemitteilung
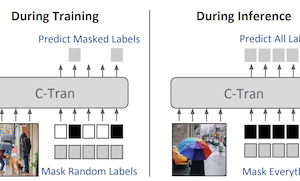
Forscher der University of Virginia haben ein neues Deep-Learning-System namens Classification Transformer (C-Tran) entwickelt, das die Fähigkeit eines Computers verbessert, mehrere Objekte oder Konzepte gleichzeitig in einem einzigen Bild zu erkennen — eine Aufgabe, die als Multi-Label-Bildklassifikation bekannt ist. Anders als die meisten bestehenden Ansätze, die jede Label-Vorhersage weitgehend isoliert behandeln oder sich auf vordefinierte Wissensgraphen stützen, um Beziehungen zwischen Labels zu erfassen, speist C-Tran sowohl Bildmerkmale als auch Label-Informationen gemeinsam in einen Transformer-Encoder ein, denselben Architekturtyp, der jüngste Fortschritte in der Verarbeitung natürlicher Sprache vorangetrieben hat. Die zentrale Innovation ist ein Trainingsverfahren namens Label Mask Training, bei dem das Modell lernt, zufällig verborgene Labels anhand teilweisen Wissens über die übrigen vorherzusagen, ähnlich wie bei den Lückentext-Übungen, die zum Trainieren von Sprachmodellen wie BERT verwendet werden. Dieser Ansatz bringt dem System bei zu verstehen, wie Labels zueinander in Beziehung stehen — zum Beispiel, dass eine Gabel und ein Messer tendenziell zusammen auftreten — ohne dass handgefertigte Regeln nötig sind. Über die Standardklassifikation hinaus kann C-Tran zur Inferenzzeit auch teilweise Label-Informationen entgegennehmen, was bedeutet, dass ein Nutzer dem Modell mitteilen kann, dass bestimmte Labels definitiv vorhanden oder abwesend sind, und genauere Vorhersagen für die verbleibenden Unbekannten erhält. Das System erzielte Ergebnisse auf dem Stand der Technik auf Benchmark-Datensätzen wie Microsoft COCO und Visual Genome und übertraf konkurrierende Methoden auch, wenn es mit teilweise bekannten oder ergänzenden Labels auf vier Datensätzen getestet wurde. Die praktische Bedeutung besteht darin, dass reale Bilder oft mit unvollständigen oder kontextuellen Metadaten — etwa Ortsmarkierungen oder Bildunterschriften — versehen sind, und C-Tran ist das erste Modell, das darauf ausgelegt ist, diese Art von teilweiser Evidenz flexibel in einem einzigen einheitlichen Framework zu nutzen.
Zusammenfassung
Multi-Label-Bildklassifikation ist die Aufgabe, eine Menge von Labels vorherzusagen, die Objekten, Attributen oder anderen in einem Bild vorhandenen Entitäten entsprechen. In dieser Arbeit schlagen wir den Classification Transformer (C-Tran) vor, ein allgemeines Framework für die Multi-Label-Bildklassifikation, das Transformer nutzt, um die komplexen Abhängigkeiten zwischen visuellen Merkmalen und Labels auszuschöpfen. Unser Ansatz besteht aus einem Transformer-Encoder, der darauf trainiert wird, eine Menge von Ziel-Labels anhand einer eingegebenen Menge maskierter Labels sowie visueller Merkmale aus einem Convolutional Neural Network vorherzusagen. Ein zentraler Bestandteil unserer Methode ist ein Trainingsziel mit Label-Masken, das ein ternäres Kodierungsschema verwendet, um den Zustand der Labels während des Trainings als positiv, negativ oder unbekannt darzustellen. Unser Modell zeigt eine Leistung auf dem Stand der Technik auf anspruchsvollen Datensätzen wie COCO und Visual Genome. Da unser Modell die Unsicherheit der Labels während des Trainings zudem explizit darstellt, ist es allgemeiner, da es uns ermöglicht, bei der Inferenz verbesserte Ergebnisse für Bilder mit teilweisen oder zusätzlichen Label-Annotationen zu erzielen. Wir demonstrieren diese zusätzliche Fähigkeit auf den Bilddatensätzen COCO, Visual Genome, News500 und CUB.
Details
Zitation
@inproceedings{lanchantin2021general,
title = {General Multi-label Image Classification with Transformers},
author = {Lanchantin, Jack and Wang, Tianlu and Ordonez, Vicente and Qi, Yanjun},
year = {2021},
booktitle = {Conference on Computer Vision and Pattern Recognition CVPR 2021},
url = {https://arxiv.org/abs/2011.14027},
}