General Multi-label Image Classification with Transformers
Resumo do comunicado de imprensa
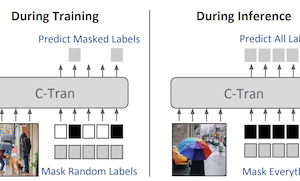
Pesquisadores da University of Virginia desenvolveram um novo sistema de aprendizado profundo, chamado Classification Transformer (C-Tran), que aprimora a capacidade de um computador de identificar simultaneamente múltiplos objetos ou conceitos dentro de uma única imagem — uma tarefa conhecida como classificação de imagens com múltiplos rótulos. Diferentemente da maioria das abordagens existentes, que tratam cada previsão de rótulo em grande parte isoladamente ou dependem de grafos de conhecimento predefinidos para capturar relações entre rótulos, o C-Tran alimenta um codificador Transformer conjuntamente com características da imagem e informações de rótulos, o mesmo tipo de arquitetura que impulsionou avanços recentes no processamento de linguagem natural. A principal inovação é um procedimento de treinamento chamado Label Mask Training, no qual o modelo aprende a prever rótulos ocultados aleatoriamente a partir do conhecimento parcial dos demais, de forma muito semelhante aos exercícios de preencher lacunas usados para treinar modelos de linguagem como o BERT. Essa abordagem ensina o sistema a entender como os rótulos se relacionam entre si — por exemplo, que um garfo e uma faca tendem a aparecer juntos — sem a necessidade de regras feitas manualmente. Além da classificação padrão, o C-Tran também pode aceitar informações parciais de rótulos no momento da inferência, o que significa que um usuário pode informar ao modelo que certos rótulos estão definitivamente presentes ou ausentes e receber previsões mais precisas para os demais desconhecidos. O sistema alcançou resultados de ponta em conjuntos de dados de referência, incluindo o Microsoft COCO e o Visual Genome, e também superou métodos concorrentes quando testado com rótulos parcialmente conhecidos ou suplementares em quatro conjuntos de dados. A relevância prática é que imagens do mundo real frequentemente vêm com metadados incompletos ou contextuais — como marcações de localização ou legendas — e o C-Tran é o primeiro modelo projetado para explorar de forma flexível esse tipo de evidência parcial dentro de um único framework unificado.
resumo
A classificação de imagens com múltiplos rótulos é a tarefa de prever um conjunto de rótulos correspondentes a objetos, atributos ou outras entidades presentes em uma imagem. Neste trabalho, propomos o Classification Transformer (C-Tran), um framework geral para classificação de imagens com múltiplos rótulos que utiliza Transformers para explorar as dependências complexas entre características visuais e rótulos. Nossa abordagem consiste em um codificador Transformer treinado para prever um conjunto de rótulos-alvo dado um conjunto de entrada de rótulos mascarados, além de características visuais provenientes de uma rede neural convolucional. Um ingrediente fundamental do nosso método é um objetivo de treinamento com máscara de rótulos que utiliza um esquema de codificação ternário para representar o estado dos rótulos como positivo, negativo ou desconhecido durante o treinamento. Nosso modelo apresenta desempenho de ponta em conjuntos de dados desafiadores como COCO e Visual Genome. Além disso, como nosso modelo representa explicitamente a incerteza dos rótulos durante o treinamento, ele é mais geral por nos permitir produzir resultados aprimorados para imagens com anotações de rótulos parciais ou adicionais durante a inferência. Demonstramos essa capacidade adicional nos conjuntos de dados de imagens COCO, Visual Genome, News500 e CUB.
detalhes
citação
@inproceedings{lanchantin2021general,
title = {General Multi-label Image Classification with Transformers},
author = {Lanchantin, Jack and Wang, Tianlu and Ordonez, Vicente and Qi, Yanjun},
year = {2021},
booktitle = {Conference on Computer Vision and Pattern Recognition CVPR 2021},
url = {https://arxiv.org/abs/2011.14027},
}