VisualNews : Benchmark and Challenges in Entity-aware Image Captioning
Résumé du communiqué de presse
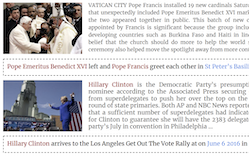
Des chercheurs de l'Université du Maryland, de l'Université de Virginie et de l'Université Rice ont publié Visual News, un jeu de données de plus d'un million d'images d'actualité associées à des textes d'articles, des légendes et des métadonnées provenant de quatre médias — The Guardian, BBC, USA Today et The Washington Post —, ce qui en fait la plus vaste collection de ce type à ce jour. Ce travail comble une véritable lacune dans la recherche sur la génération de légendes d'images : les jeux de données existants comme Microsoft COCO entraînent les modèles à produire des descriptions génériques telles que « un groupe de personnes tenant des parapluies rouges », qui ne parviennent pas à saisir le qui, le où et le quoi qui donnent du sens à une photo d'actualité. Pour exploiter ce jeu de données, l'équipe a également construit Visual News Captioner, un modèle fondé sur l'architecture Transformer qui s'appuie à la fois sur l'image et sur le texte de l'article associé pour générer des légendes contenant des entités nommées précises — personnes, lieux et organisations — plutôt que de vagues termes génériques. Le modèle introduit plusieurs ajouts techniques, notamment un mécanisme d'« Attention sur l'Attention », une Couche Sélective Visuelle qui relie les caractéristiques de l'image et du texte lors de l'encodage, et une étape de Nettoyage de Balises pour traiter les mots rares ne figurant pas dans le vocabulaire du modèle. Testé face à des approches concurrentes sur trois jeux de données, Visual News Captioner a égalé ou dépassé l'état de l'art sur les métriques standard de génération de légendes tout en utilisant environ la moitié du nombre de paramètres de son rival le plus proche. Les chercheurs ont également constaté que les modèles entraînés sur les données d'une agence de presse se comportaient nettement moins bien lorsqu'ils étaient testés sur le contenu d'une autre agence, soulignant à quel point le style d'écriture et la ligne éditoriale varient d'une rédaction à l'autre — et à quel point le problème devient plus ardu dans un contexte véritablement diversifié.
résumé
Nous proposons Visual News Captioner, un modèle conscient des entités pour la tâche de génération de légendes d'images d'actualité. Nous introduisons également Visual News, un benchmark à grande échelle composé de plus d'un million d'images d'actualité accompagnées des articles de presse associés, des légendes d'images, des informations sur les auteurs et d'autres métadonnées. Contrairement à la tâche standard de génération de légendes d'images, les images d'actualité représentent des situations où les personnes, les lieux et les événements revêtent une importance primordiale. Notre méthode proposée peut combiner efficacement des caractéristiques visuelles et textuelles pour générer des légendes contenant des informations plus riches telles que des événements et des entités. Plus précisément, construit sur l'architecture Transformer, notre modèle est en outre doté de nouvelles techniques de fusion de caractéristiques multimodales et de mécanismes d'attention, conçus pour générer les entités nommées avec plus de précision. Notre méthode utilise beaucoup moins de paramètres tout en obtenant des résultats de prédiction légèrement meilleurs que les méthodes concurrentes. Notre jeu de données Visual News, plus vaste et plus diversifié, met davantage en lumière les défis qui subsistent dans la génération de légendes d'images d'actualité.
détails
citation
@inproceedings{liu2021visualnews,
title = {VisualNews : Benchmark and Challenges in Entity-aware Image Captioning},
author = {Liu, Fuxiao and Wang, Yinghan and Wang, Tianlu and Ordonez, Vicente},
year = {2021},
booktitle = {Empirical Methods in Natural Language Processing. EMNLP 2021},
url = {https://arxiv.org/abs/2010.03743},
}