Cette démo tente de mettre en évidence des zones d'une image en fonction d'un texte d'entrée arbitraire.
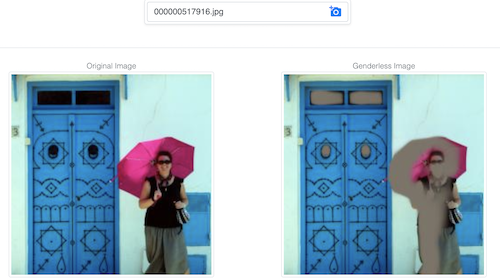
Cette démo tente de rendre difficile la prédiction du genre à partir d'une image par un modèle, en la modifiant de sorte que cette tâche devienne plus ardue tout en conservant l'essentiel de l'information de l'image.
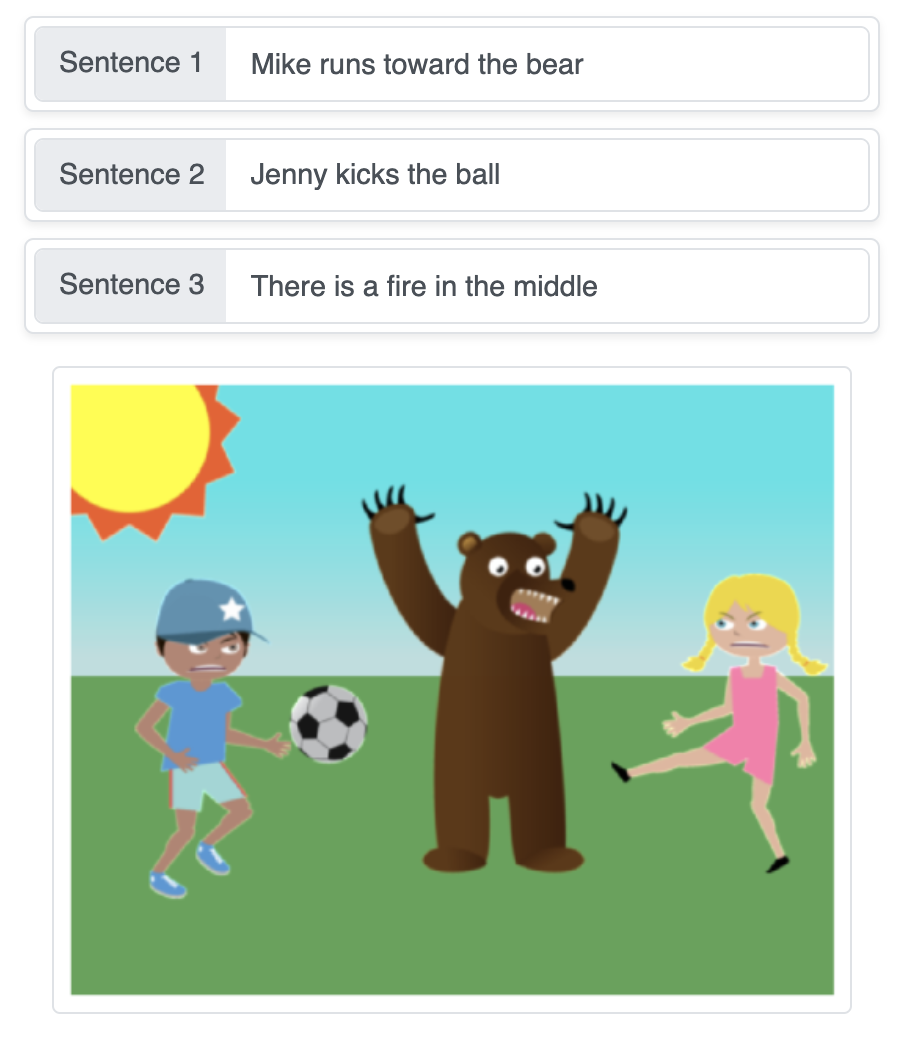
Cette démo transforme des descriptions textuelles en une scène générée automatiquement, en assemblant des objets de manière séquentielle sur un fond uni, étape par étape, à l'aide de réseaux de neurones de génération de séquences.
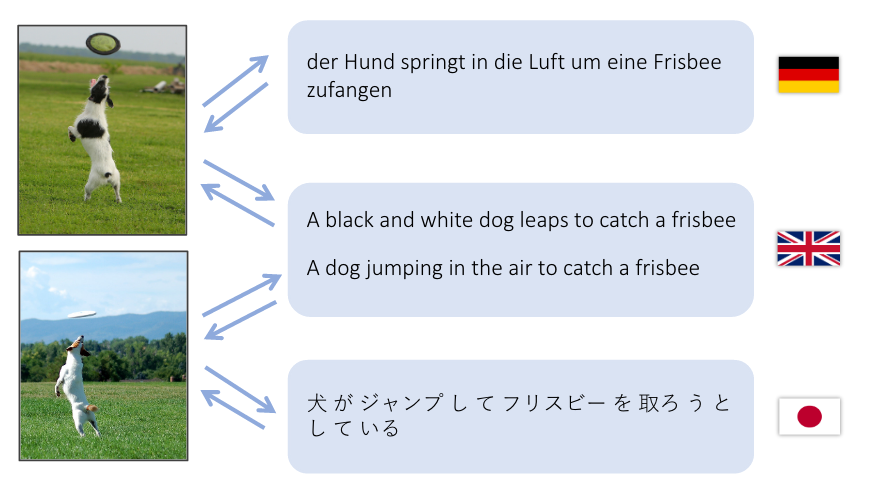
Cette démo tente de traduire une phrase en anglais dans un espace de caractéristiques visuelles ainsi qu'en une phrase à la fois en allemand (Deutsch) et en japonais (日本語).
Recherchez des images par texte dans le jeu de données SBU Captions, qui contient 1 million d'images avec des légendes issues de Flickr et a été utilisé dans de nombreux projets.
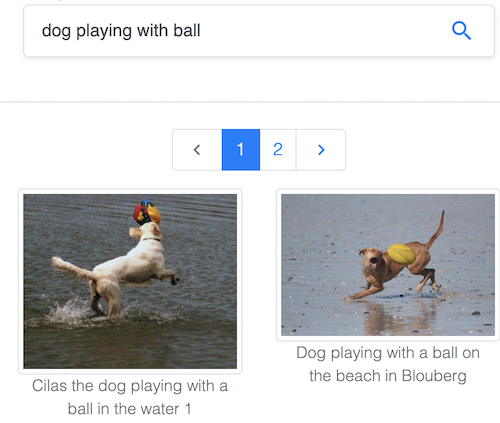
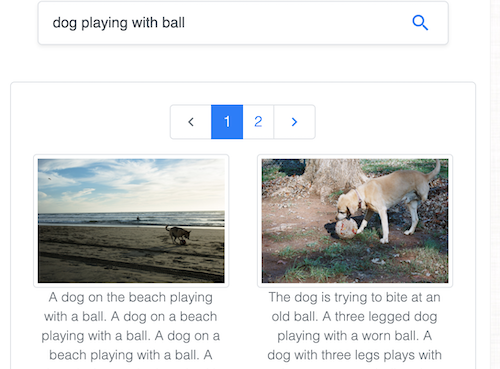
Recherchez des images par texte dans le célèbre jeu de données Common Objects in Context (COCO), maintenu par la Common Visual Data Foundation.