보도 자료 요약
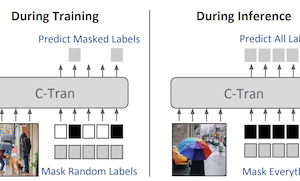
버지니아 대학교의 연구진은 단일 이미지 내에서 여러 객체나 개념을 동시에 식별하는 — 다중 레이블 이미지 분류로 알려진 작업 — 컴퓨터의 능력을 향상시키는 Classification Transformer (C-Tran)이라는 새로운 딥러닝 시스템을 개발했다. 각 레이블 예측을 대체로 개별적으로 다루거나 레이블 간 관계를 포착하기 위해 미리 정의된 지식 그래프에 의존하는 대부분의 기존 접근법과 달리, C-Tran은 이미지 특징과 레이블 정보를 모두 Transformer 인코더에 함께 입력하는데, 이는 최근 자연어 처리의 발전을 이끈 것과 동일한 유형의 아키텍처이다. 핵심 혁신은 Label Mask Training이라는 학습 절차로, 모델이 다른 레이블들에 대한 부분적 지식이 주어졌을 때 무작위로 숨겨진 레이블을 예측하는 법을 학습하는데, 이는 BERT와 같은 언어 모델을 학습하는 데 사용되는 빈칸 채우기 연습과 매우 유사하다. 이 접근법은 손으로 만든 규칙 없이도 시스템이 레이블들이 서로 어떻게 관련되는지를 — 예를 들어 포크와 나이프가 함께 나타나는 경향이 있다는 것을 — 이해하도록 가르친다. 표준 분류를 넘어, C-Tran은 추론 시점에 부분적인 레이블 정보도 받아들일 수 있는데, 이는 사용자가 모델에게 특정 레이블이 확실히 존재하거나 부재한다고 알려주고 나머지 미지의 것들에 대해 더 정확한 예측을 받을 수 있음을 의미한다. 이 시스템은 Microsoft COCO와 Visual Genome을 포함한 벤치마크 데이터셋에서 최첨단 결과를 달성했으며, 네 개의 데이터셋에서 부분적으로 알려졌거나 보충적인 레이블로 테스트했을 때도 경쟁 방법들을 능가했다. 실용적 의의는 실세계 이미지가 흔히 — 위치 태그나 캡션 같은 — 불완전하거나 맥락적인 메타데이터와 함께 제공되며, C-Tran이 단일 통합 프레임워크 내에서 그런 종류의 부분적 증거를 유연하게 활용하도록 설계된 최초의 모델이라는 점이다.
초록
다중 레이블 이미지 분류는 이미지에 존재하는 객체, 속성 또는 기타 개체에 해당하는 레이블 집합을 예측하는 작업이다. 본 연구에서 우리는 Transformer를 활용하여 시각적 특징과 레이블 간의 복잡한 의존성을 이용하는 다중 레이블 이미지 분류를 위한 범용 프레임워크인 Classification Transformer (C-Tran)을 제안한다. 우리 접근법은 마스킹된 레이블의 입력 집합과 합성곱 신경망의 시각적 특징이 주어졌을 때 목표 레이블 집합을 예측하도록 학습된 Transformer 인코더로 구성된다. 우리 방법의 핵심 요소는 학습 중에 레이블의 상태를 양성, 음성, 또는 미지(unknown)로 나타내기 위해 삼진(ternary) 인코딩 방식을 사용하는 레이블 마스크 학습 목표이다. 우리 모델은 COCO 및 Visual Genome과 같은 도전적인 데이터셋에서 최첨단 성능을 보인다. 더욱이, 우리 모델은 학습 중에 레이블의 불확실성을 명시적으로 표현하기 때문에, 추론 중에 부분적이거나 추가적인 레이블 주석이 있는 이미지에 대해 향상된 결과를 산출할 수 있게 하여 더 범용적이다. 우리는 COCO, Visual Genome, News500, CUB 이미지 데이터셋에서 이 추가 기능을 입증한다.
세부 정보
인용
@inproceedings{lanchantin2021general,
title = {General Multi-label Image Classification with Transformers},
author = {Lanchantin, Jack and Wang, Tianlu and Ordonez, Vicente and Qi, Yanjun},
year = {2021},
booktitle = {Conference on Computer Vision and Pattern Recognition CVPR 2021},
url = {https://arxiv.org/abs/2011.14027},
}