보도 자료 요약
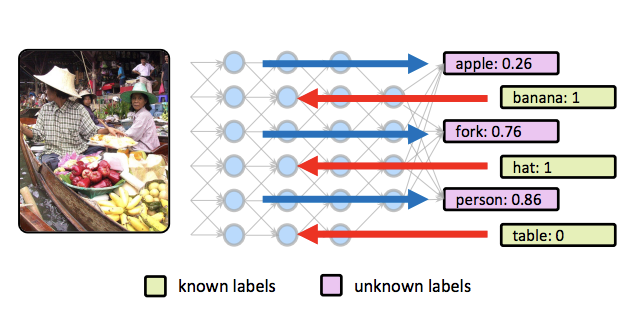
버지니아 대학교와 CyberAgent의 연구진은 사진에 관한 일부 정보가 미리 알려져 있을 때 기존의 이미지 인식 신경망이 더 나은 예측을 할 수 있게 하는 기법을 개발하였다. feedback-prop이라 불리는 이 방법은 컴퓨터 비전 시스템이 일반적으로 테스트되는 방식, 즉 시각 입력만 사용하는 방식과, 주변 텍스트, GPS 데이터, 사용자 태그, 또는 기타 문맥적 단서가 흔히 이용 가능한 실제 사용 방식 사이의 간극을 다룬다. 연구진은 그러한 추가 정보를 통합하기 위해 네트워크를 재학습하는 대신, 추론 단계 자체에서 알려진 레이블을 학습된 네트워크에 다시 통과시켜, 남아 있는 미지의 레이블에 대한 예측이 개선될 때까지 네트워크의 내부 활성화를 조정할 수 있음을 발견하였다. 이들은 이 접근법의 두 가지 변형, 즉 계층을 순차적으로 갱신하는 것과 여러 계층에 동시에 작은 교정 변수를 주입하는 것을, 일부 레이블이 이미 알려져 있을 때 이미지 속 객체를 식별하는 것, 거친 범주가 주어졌을 때 세밀한 장면 범주를 예측하는 것, 객체 주석이 이용 가능할 때 이미지 캡션을 생성하는 것을 포함한 여러 과제에 걸쳐 테스트하였다. VGG-16 및 ResNet을 포함한 여러 표준 네트워크 아키텍처와 모든 과제에 걸쳐, 부분 증거를 추가하는 것은 일관되게 정확도를 개선하였으며, 상대적 향상은 과제에 따라 약 10%에서 13%에 이르렀다. 특히 이 기법은 원래 모델의 학습에 어떠한 변경도 요구하지 않으며 알려진 레이블과 미지의 레이블의 임의 조합과 함께 작동하여, 이미지가 어떠한 동반 문맥도 없이 도착하는 경우가 드문 실세계 배포 시나리오에 광범위하게 실용적이다.
초록
우리는 부분적인 증거가 이용 가능할 때 심층 합성곱 신경망(CNN)을 위한 추론 절차를 제안한다. 우리의 방법은 겹치지 않는 임의의 목표 레이블 집합에 대한 값이 알려져 있을 때, 또 다른 임의의 미지의 목표 레이블 집합에 대한 예측 정확도를 높이는 일반적인 피드백 기반 전파 접근법(feedback-prop)으로 구성된다. 우리는 다중 레이블 또는 다중 태스크 설정으로 학습된 기존 모델이 어떠한 재학습이나 파인튜닝 없이도 feedback-prop을 손쉽게 활용할 수 있음을 보인다. 우리의 feedback-prop 추론 절차는 일반적이고, 단순하며, 신뢰할 수 있고, 다양한 어려운 시각 인식 과제에서 작동한다. 우리는 계층별 및 잔차 반복 갱신에 기반한 feedback-prop의 두 가지 변형을 제시한다. 우리는 여러 다중 태스크 모델을 사용하여 실험하고 feedback-prop이 그 모두에서 효과적임을 보인다. 우리의 결과는 이전에 보고되지 않았으나 흥미로운, 심층 CNN의 동적 성질을 드러낸다. 우리는 또한 일반적인 시각 인식 과제에서 부분 증거 하의 추론을 위해 이 성질을 활용하는 관련 기술적 접근법을 제시한다.
세부 정보
인용
@inproceedings{wang2018feedback,
title = {Feedback-prop: Convolutional Neural Network Inference under Partial Evidence},
author = {Wang, Tianlu and Yamaguchi, Kota and Ordonez, Vicente},
year = {2018},
booktitle = {Conference on Computer Vision and Pattern Recognition. CVPR 2018},
url = {https://arxiv.org/abs/1710.08049},
}