LoCoRe: Image Re-ranking with Long-Context Sequence Modeling
Resumo do comunicado de imprensa
Pesquisadores da Rice University e da Universidade Técnica Tcheca de Praga desenvolveram um novo sistema de recuperação de imagens chamado LOCORE que repensa como os mecanismos de busca filtram e reordenam imagens candidatas após uma busca inicial ampla. Os sistemas de reordenação tradicionais comparam uma imagem de consulta com cada imagem candidata individualmente, um par de cada vez, o que significa que perdem relações úteis entre as próprias imagens candidatas — por exemplo, o fato de que duas imagens de galeria podem compartilhar características que, juntas, fornecem evidências mais fortes de correspondência. Em vez disso, o LOCORE processa a consulta junto com toda uma lista reduzida de até 100 imagens candidatas simultaneamente, usando um modelo transformer de longo contexto chamado Longformer, originalmente desenvolvido para documentos de texto extensos, para capturar essas dependências entre imagens no nível de descritores visuais locais de granularidade fina. Para lidar com situações em que a lista reduzida excede o que o modelo consegue acomodar na memória de uma só vez, a equipe projetou uma estratégia de janela deslizante que percorre a lista de candidatos em blocos sobrepostos. Em testes em cinco conjuntos de dados de benchmark cobrindo pontos de referência, produtos, itens de moda e espécies de aves, o LOCORE superou consistentemente os métodos de reordenação existentes, incluindo abordagens par a par usando descritores locais e abordagens em nível de lista usando descritores globais, enquanto operava com latência comparável ou inferior e usava significativamente menos memória. O trabalho é relevante porque uma melhor reordenação melhora diretamente a precisão dos sistemas de busca de imagens, e a abordagem demonstra que ideias do processamento de linguagem natural — particularmente a modelagem de longo contexto e a classificação em nível de token — podem ser transferidas de forma eficaz para tarefas de recuperação visual.
resumo
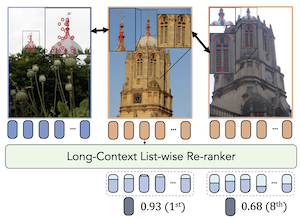
Apresentamos o LOCORE, Long-Context Re-ranker, um modelo que recebe como entrada descritores locais correspondentes a uma consulta de imagem e a uma lista de imagens de galeria e produz pontuações de similaridade entre a consulta e cada imagem da galeria. Esse modelo é usado para recuperação de imagens, em que tipicamente uma primeira ordenação é realizada com uma medida de similaridade eficiente, e em seguida uma lista reduzida das imagens mais bem ranqueadas é reordenada com base em uma medida de similaridade de granularidade mais fina. Em comparação com métodos existentes que realizam estimativa de similaridade par a par com descritores locais ou reordenação em nível de lista com descritores globais, o LOCORE é o primeiro método a realizar a reordenação em nível de lista com descritores locais. Para isso, aproveitamos modelos de sequência de longo contexto eficientes para capturar de forma eficaz as dependências entre a consulta e as imagens da galeria no nível dos descritores locais. Durante os testes, processamos listas reduzidas longas com uma estratégia de janela deslizante adaptada para superar as limitações de tamanho de contexto dos modelos de sequência. Nossa abordagem alcança desempenho superior em comparação com outros reordenadores em benchmarks consagrados de recuperação de imagens de pontos de referência (ROxf e RPar), produtos (SOP), itens de moda (In-Shop) e espécies de aves (CUB-200), mantendo uma latência comparável à dos reordenadores par a par com descritores locais.
detalhes
citação
@inproceedings{xiao2025locore,
title = {LoCoRe: Image Re-ranking with Long-Context Sequence Modeling},
author = {Xiao, Zilin and Suma, Pavel and Sachdeva, Ayush and Wang, Hao-Jen and Kordopatis-Zilos, Giorgos and Tolias, Giorgos and Ordonez, Vicente},
year = {2025},
booktitle = {Conf. on Computer Vision and Pattern Recognition. CVPR 2025},
url = {https://arxiv.org/abs/2503.21772},
}
perguntas, principais contribuições e limitações deste artigo geradas automaticamente
Perguntas que este artigo ajuda a responder
- O que é o LOCORE e qual problema ele aborda? O LOCORE é um modelo de reordenação de imagens de longo contexto que processa conjuntamente uma imagem de consulta e uma lista reduzida de imagens de galeria usando descritores locais, melhorando a ordenação de segundo estágio usada em sistemas de recuperação de imagens.
- Como o LOCORE difere dos reordenadores par a par? Os métodos par a par comparam a consulta com cada imagem de galeria de forma independente, enquanto o LOCORE modela toda a lista reduzida em conjunto, de modo que pode explorar tanto as relações entre as imagens de galeria quanto as correspondências consulta-galeria.
- Por que o LOCORE usa um modelo de sequência de longo contexto? Reordenar até 100 imagens de galeria com descritores locais cria uma longa sequência de tokens, e a atenção no estilo Longformer permite que o modelo capture dependências úteis com memória e latência gerenciáveis.
- Como o LOCORE lida com listas reduzidas maiores do que sua janela de contexto? Ele usa uma estratégia de janela deslizante sobreposta que reutiliza o reordenador em nível de lista ao longo de partes da lista reduzida, permitindo que o método melhore as ordenações além do tamanho máximo de lista visto em uma única passagem direta.
- Quais benchmarks de recuperação o LOCORE melhora? O artigo relata resultados de reordenação líderes ou de ponta em benchmarks de recuperação de pontos de referência, produtos, moda e espécies de aves, incluindo ROxf/RPar, SOP, In-Shop e CUB-200.
Principais contribuições
- O artigo introduz o primeiro framework de reordenação de imagens em nível de lista que opera no nível dos descritores locais, em vez de depender de correspondência local par a par ou de descritores globais em nível de lista.
- O LOCORE reformula a reordenação de imagens como um problema de classificação em nível de token de longo contexto, transferindo ideias da extração de spans e da rotulagem de sequências do PLN para a recuperação visual.
- O modelo usa atenção global da consulta, tokens separadores e treinamento com galeria embaralhada para evitar atalhos posicionais e aprender interações significativas entre descritores de diferentes imagens.
- Em ROxf/RPar e em suas variantes com 1M de distratores, o LOCORE melhora em relação a reordenadores anteriores baseados em descritores locais, como verificação geométrica, RRT, CVNet e AMES, sob configurações de descritor comparáveis.
- O método também melhora benchmarks de recuperação por aprendizado de métrica, incluindo CUB-200, SOP e In-Shop, mostrando que a reordenação em nível de lista com descritores locais é útil para além da recuperação de pontos de referência.
Limitações e ressalvas
- O LOCORE é um reordenador de segundo estágio, e não um substituto para a recuperação eficiente de primeiro estágio, o que é apropriado para pipelines de busca de larga escala em que um descritor global compacto primeiro reduz a lista de candidatos.
- O método depende de descritores locais de alta qualidade de sistemas como DELG ou DINOv2, mas isso o torna complementar aos avanços na extração de características locais, em vez de atrelado a um único backbone.
- O processamento de longo contexto tem uma janela de contexto finita, então listas reduzidas muito longas exigem inferência por janela deslizante; o artigo mostra que essa estratégia funciona bem e pode estender os benefícios para além do tamanho da lista de treinamento.
- O treinamento exige cuidado para evitar atalhos posicionais da ordenação global inicial, mas o treinamento com galeria embaralhada é uma correção simples e eficaz demonstrada nas ablações.
- A avaliação foca em benchmarks consagrados de recuperação em nível de instância, deixando cenários de busca de produção mais amplos e coleções de imagens específicas de domínio como próximos estudos naturais de implantação.
Como interpretar este resultado
Este artigo é mais bem compreendido como uma forte contribuição para a reordenação na recuperação de imagens: o LOCORE mostra que a modelagem em nível de lista de longo contexto pode tornar os descritores locais mais poderosos, melhorando a precisão em diversos benchmarks ao mesmo tempo em que mantém a latência e a memória práticas para a recuperação de segundo estágio.