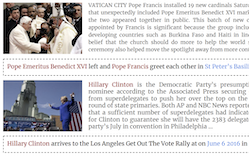
VisualNews : Benchmark and Challenges in Entity-aware Image Captioning
Краткое изложение пресс-релиза
Исследователи из University of Maryland, University of Virginia и Rice University выпустили Visual News — набор данных из более чем одного миллиона новостных изображений в паре с текстом статей, подписями и метаданными, взятыми из четырёх изданий — The Guardian, BBC, USA Today и The Washington Post, — что делает его крупнейшей коллекцией такого рода на сегодняшний день. Работа устраняет реальный пробел в исследованиях генерации подписей к изображениям: существующие наборы данных, такие как Microsoft COCO, обучают модели создавать обобщённые описания вроде «группа людей, держащих красные зонты», которые не передают «кто», «где» и «что», придающие новостной фотографии смысл. Чтобы применить набор данных на практике, команда также создала Visual News Captioner — модель на основе Transformer, которая черпает информацию как из изображения, так и из сопровождающего текста статьи, чтобы генерировать подписи, содержащие конкретные именованные сущности — людей, места и организации — вместо расплывчатых заполнителей. Модель вводит несколько технических дополнений, включая механизм «Attention on Attention», Visual Selective Layer, который связывает признаки изображения и текста при кодировании, и этап Tag-Cleaning для обработки редких слов, выходящих за пределы словаря модели. Протестированный против конкурирующих подходов на трёх наборах данных, Visual News Captioner сравнялся или превзошёл современный уровень по стандартным метрикам генерации подписей, используя при этом примерно вдвое меньше параметров, чем его ближайший конкурент. Исследователи также обнаружили, что модели, обученные на данных одного новостного агентства, заметно хуже работали при тестировании на контенте другого агентства, что подчёркивает, насколько сильно различаются стиль письма и редакционная направленность в разных редакциях — и насколько труднее становится задача в по-настоящему разнообразной обстановке.
аннотация
Мы предлагаем Visual News Captioner — модель с учётом сущностей для задачи генерации подписей к новостным изображениям. Мы также представляем Visual News — крупномасштабный бенчмарк, состоящий из более чем одного миллиона новостных изображений вместе со связанными новостными статьями, подписями к изображениям, информацией об авторах и другими метаданными. В отличие от стандартной задачи генерации подписей к изображениям, новостные изображения отображают ситуации, в которых люди, места и события имеют первостепенное значение. Наш предложенный метод способен эффективно сочетать визуальные и текстовые признаки для генерации подписей с более богатой информацией, такой как события и сущности. В частности, построенная на архитектуре Transformer, наша модель дополнительно оснащена новыми техниками слияния мультимодальных признаков и механизмами внимания, которые предназначены для более точной генерации именованных сущностей. Наш метод использует гораздо меньше параметров, достигая при этом несколько лучших результатов предсказания, чем конкурирующие методы. Наш более крупный и разнообразный набор данных Visual News дополнительно подчёркивает остающиеся трудности в генерации подписей к новостным изображениям.
подробности
цитирование
@inproceedings{liu2021visualnews,
title = {VisualNews : Benchmark and Challenges in Entity-aware Image Captioning},
author = {Liu, Fuxiao and Wang, Yinghan and Wang, Tianlu and Ordonez, Vicente},
year = {2021},
booktitle = {Empirical Methods in Natural Language Processing. EMNLP 2021},
url = {https://arxiv.org/abs/2010.03743},
}