Это демо пытается выделить области изображения в зависимости от произвольного входного текста.
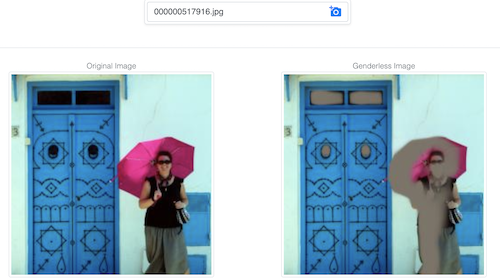
Это демо пытается затруднить модели предсказание пола по изображению, изменяя его так, чтобы эта задача стала сложнее, сохраняя при этом большую часть информации изображения.
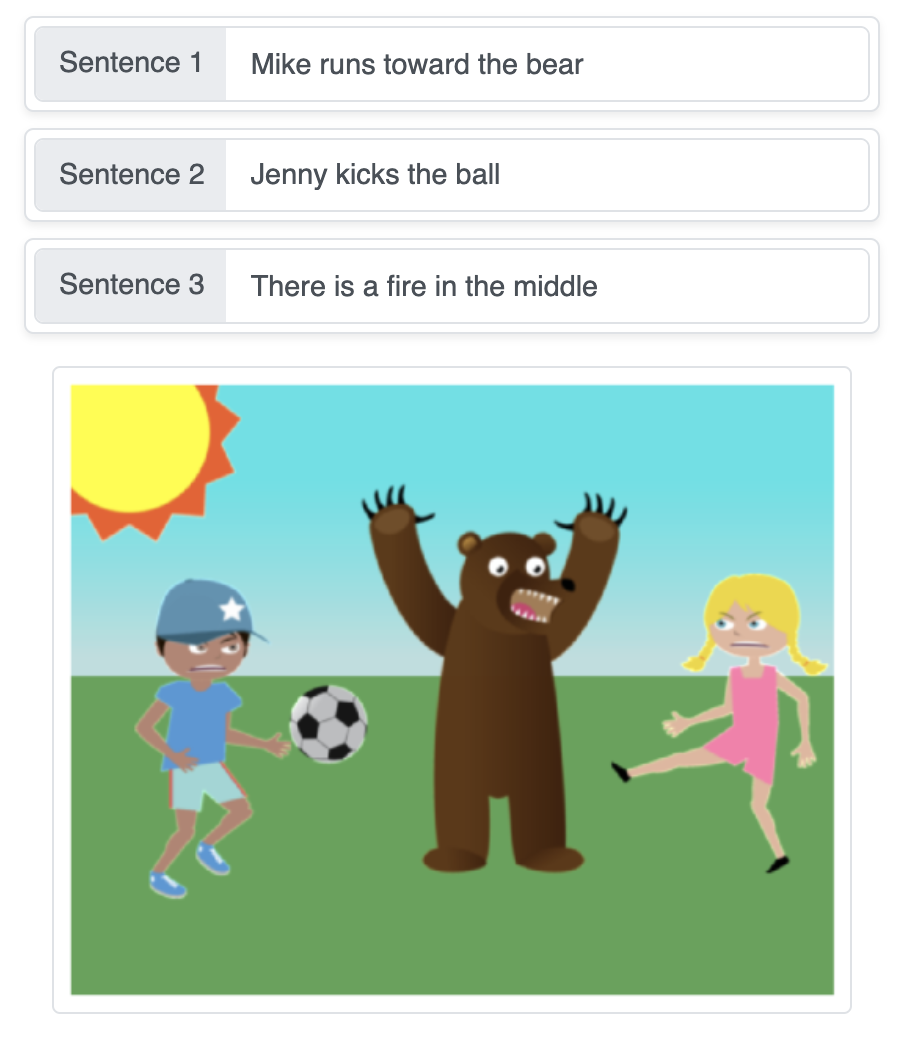
Это демо превращает текстовые описания в сцену, создаваемую автоматически путём последовательного размещения объектов на однотонном фоне шаг за шагом с помощью нейронных сетей генерации последовательностей.
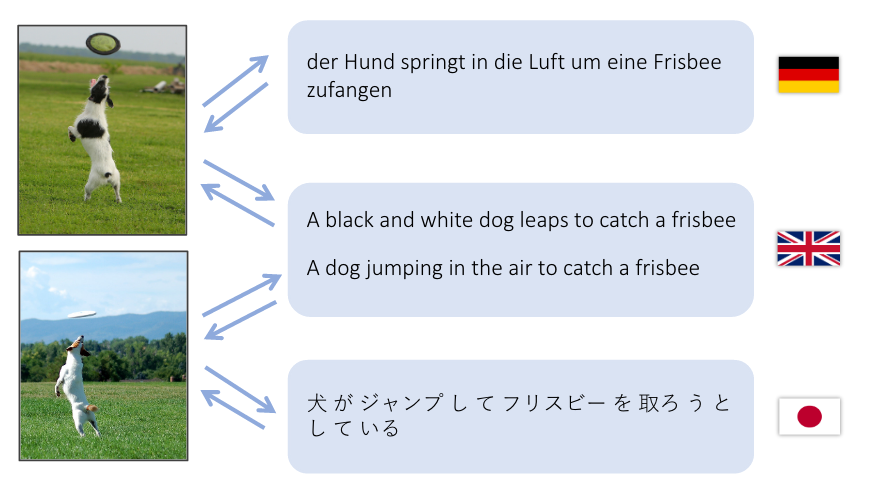
Это демо пытается перевести предложение с английского языка в пространство визуальных признаков, а также в предложение на немецком (Deutsch) и японском (日本語) языках.
Поиск изображений по тексту в наборе данных SBU Captions, который содержит 1 миллион изображений с подписями из Flickr и использовался во многих проектах
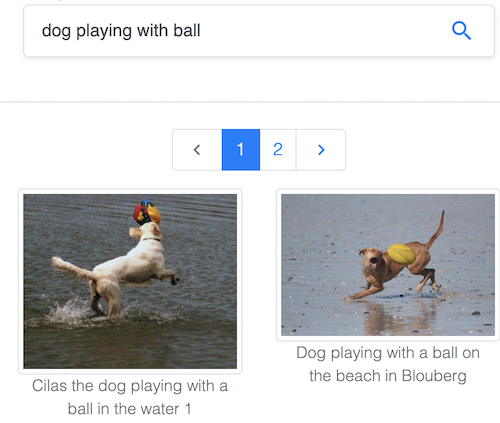
Поиск изображений по тексту в популярном наборе данных Common Objects in Context (COCO), поддерживаемом Common Visual Data Foundation.