VisualNews : Benchmark and Challenges in Entity-aware Image Captioning
Tóm tắt thông cáo báo chí
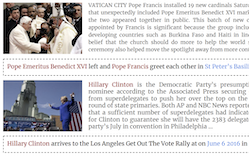
Các nhà nghiên cứu tại University of Maryland, University of Virginia, và Rice University đã phát hành Visual News, một tập dữ liệu gồm hơn một triệu ảnh tin tức được ghép với văn bản bài báo, chú thích, và siêu dữ liệu được lấy từ bốn hãng tin — The Guardian, BBC, USA Today, và The Washington Post — khiến nó trở thành bộ sưu tập lớn nhất thuộc loại này cho đến nay. Công trình này giải quyết một khoảng trống thực sự trong nghiên cứu chú thích ảnh: các tập dữ liệu hiện có như Microsoft COCO huấn luyện các mô hình tạo ra những mô tả chung chung như "một nhóm người cầm ô đỏ", vốn không nắm bắt được ai, ở đâu, và cái gì khiến một bức ảnh tin tức có ý nghĩa. Để đưa tập dữ liệu vào sử dụng, nhóm nghiên cứu cũng xây dựng Visual News Captioner, một mô hình dựa trên Transformer rút từ cả ảnh lẫn văn bản bài báo đi kèm để sinh các chú thích chứa các thực thể có tên cụ thể — con người, địa điểm, và tổ chức — thay vì các từ thay thế mơ hồ. Mô hình giới thiệu một số bổ sung kỹ thuật, bao gồm một cơ chế "Attention on Attention", một Visual Selective Layer liên kết các đặc trưng ảnh và văn bản trong quá trình mã hóa, và một bước Tag-Cleaning để xử lý các từ hiếm nằm ngoài vốn từ vựng của mô hình. Được kiểm thử so với các cách tiếp cận cạnh tranh trên ba tập dữ liệu, Visual News Captioner sánh ngang hoặc đánh bại trình độ tốt nhất hiện nay trên các chỉ số chú thích tiêu chuẩn trong khi sử dụng khoảng một nửa số tham số của đối thủ gần nhất. Các nhà nghiên cứu cũng phát hiện ra rằng các mô hình được huấn luyện trên dữ liệu từ một hãng tin hoạt động kém hơn rõ rệt khi được kiểm thử trên nội dung của một hãng khác, nhấn mạnh phong cách viết và trọng tâm biên tập thay đổi nhiều đến mức nào giữa các tòa soạn — và bài toán trở nên khó hơn nhiều đến mức nào trong một bối cảnh thực sự đa dạng.
tóm tắt
Chúng tôi đề xuất Visual News Captioner, một mô hình nhận biết thực thể (entity-aware) cho tác vụ chú thích ảnh tin tức. Chúng tôi cũng giới thiệu Visual News, một benchmark quy mô lớn bao gồm hơn một triệu ảnh tin tức cùng với các bài báo liên quan, chú thích ảnh, thông tin tác giả, và các siêu dữ liệu khác. Khác với tác vụ chú thích ảnh tiêu chuẩn, các ảnh tin tức mô tả những tình huống mà con người, địa điểm, và sự kiện có tầm quan trọng tối cao. Phương pháp đề xuất của chúng tôi có thể kết hợp hiệu quả các đặc trưng thị giác và văn bản để sinh các chú thích với thông tin phong phú hơn như sự kiện và thực thể. Cụ thể hơn, được xây dựng trên kiến trúc Transformer, mô hình của chúng tôi còn được trang bị thêm các kỹ thuật hợp nhất đặc trưng đa phương thức mới lạ và các cơ chế chú ý, vốn được thiết kế để sinh các thực thể có tên (named entity) chính xác hơn. Phương pháp của chúng tôi sử dụng ít tham số hơn nhiều trong khi đạt kết quả dự đoán tốt hơn một chút so với các phương pháp cạnh tranh. Tập dữ liệu Visual News lớn hơn và đa dạng hơn của chúng tôi còn làm nổi bật những thách thức còn lại trong việc chú thích ảnh tin tức.
chi tiết
trích dẫn
@inproceedings{liu2021visualnews,
title = {VisualNews : Benchmark and Challenges in Entity-aware Image Captioning},
author = {Liu, Fuxiao and Wang, Yinghan and Wang, Tianlu and Ordonez, Vicente},
year = {2021},
booktitle = {Empirical Methods in Natural Language Processing. EMNLP 2021},
url = {https://arxiv.org/abs/2010.03743},
}