Demo này cố gắng làm nổi bật các vùng của một bức ảnh dựa trên một đoạn văn bản đầu vào tùy ý.
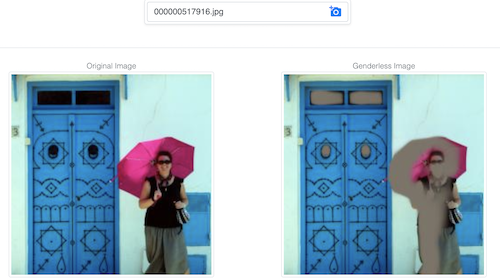
Demo này cố gắng khiến cho một mô hình khó dự đoán giới tính từ một bức ảnh bằng cách chỉnh sửa ảnh sao cho nhiệm vụ này trở nên khó khăn hơn trong khi vẫn giữ lại phần lớn thông tin của ảnh.
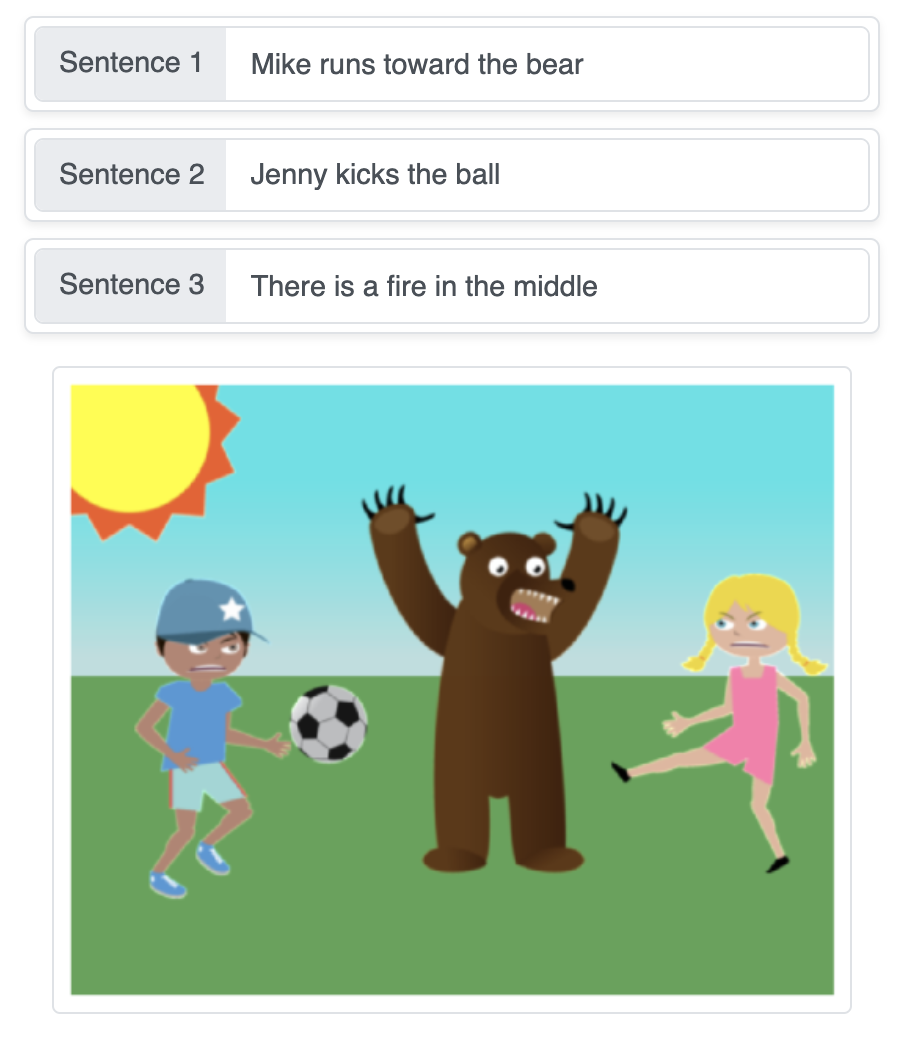
Demo này biến các mô tả bằng văn bản thành một cảnh được tạo tự động bằng cách ghép các đối tượng tuần tự lên một nền trơn theo từng bước, sử dụng mạng nơ-ron sinh chuỗi.
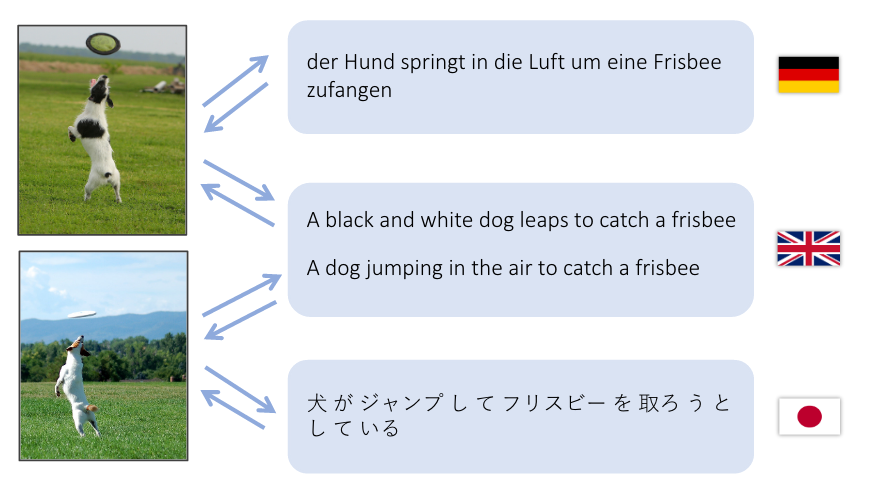
Demo này cố gắng dịch một câu tiếng Anh sang không gian đặc trưng thị giác và sang một câu trong cả tiếng Đức (Deutsch) lẫn tiếng Nhật (日本語).
Tìm kiếm ảnh bằng văn bản trong bộ dữ liệu SBU Captions, gồm 1 triệu ảnh kèm chú thích từ Flickr và đã được sử dụng trong nhiều dự án.
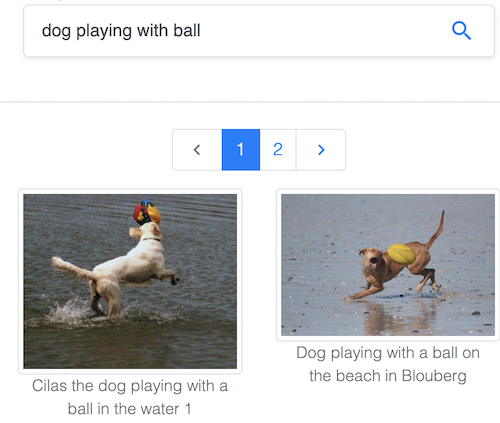
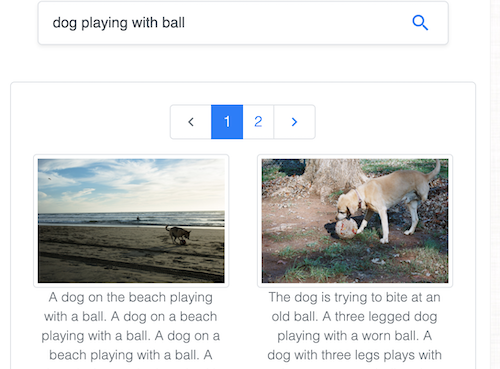
Tìm kiếm ảnh bằng văn bản trong bộ dữ liệu phổ biến Common Objects in Context (COCO) được duy trì bởi Common Visual Data Foundation.