新闻稿摘要
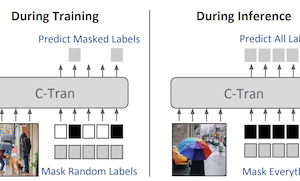
弗吉尼亚大学的研究人员开发了一种新的深度学习系统,称为 Classification Transformer(C-Tran),它提升了计算机在单张图像中同时识别多个物体或概念的能力——这一任务被称为多标签图像分类。与大多数现有方法不同(它们要么基本上孤立地处理每个标签预测,要么依赖预定义的知识图谱来捕捉标签之间的关系),C-Tran 将图像特征和标签信息共同输入到一个 Transformer 编码器中,这正是推动自然语言处理近期进展的同一类架构。其关键创新是一种名为 Label Mask Training 的训练过程,在该过程中,模型学习在已知其他标签部分信息的情况下预测随机隐藏的标签,这很像用于训练 BERT 等语言模型的填空练习。这种方法教会系统理解标签之间如何相互关联——例如,叉子和刀往往一起出现——而无需手工制定规则。除了标准分类之外,C-Tran 还可以在推理时接受部分标签信息,这意味着用户可以告诉模型某些标签确定存在或不存在,从而为其余未知标签获得更准确的预测。该系统在包括 Microsoft COCO 和 Visual Genome 在内的基准数据集上取得了最先进的结果,并且在四个数据集上使用部分已知或补充标签进行测试时,也优于竞争方法。其实际意义在于,真实世界的图像往往附带不完整或上下文相关的元数据——例如位置标签或字幕——而 C-Tran 是首个被设计为能在单一统一框架内灵活利用这类部分证据的模型。
摘要
多标签图像分类是指预测对应于图像中存在的物体、属性或其他实体的一组标签的任务。在这项工作中,我们提出了 Classification Transformer(C-Tran),这是一个用于多标签图像分类的通用框架,它利用 Transformer 来挖掘视觉特征与标签之间的复杂依赖关系。我们的方法由一个 Transformer 编码器组成,该编码器经训练,在给定一组被掩码标签的输入和来自卷积神经网络的视觉特征的情况下,预测一组目标标签。我们方法的一个关键要素是标签掩码训练目标,它使用三元编码方案在训练期间将标签的状态表示为正、负或未知。我们的模型在 COCO 和 Visual Genome 等具有挑战性的数据集上展现出最先进的性能。此外,由于我们的模型在训练期间显式地表示了标签的不确定性,它更具通用性,使我们能够在推理时为带有部分或额外标签标注的图像产生更优的结果。我们在 COCO、Visual Genome、News500 和 CUB 图像数据集上展示了这一额外能力。
详情
引用
@inproceedings{lanchantin2021general,
title = {General Multi-label Image Classification with Transformers},
author = {Lanchantin, Jack and Wang, Tianlu and Ordonez, Vicente and Qi, Yanjun},
year = {2021},
booktitle = {Conference on Computer Vision and Pattern Recognition CVPR 2021},
url = {https://arxiv.org/abs/2011.14027},
}