PropTest: Automatic Property Testing for Improved Visual Programming
Zusammenfassung der Pressemitteilung
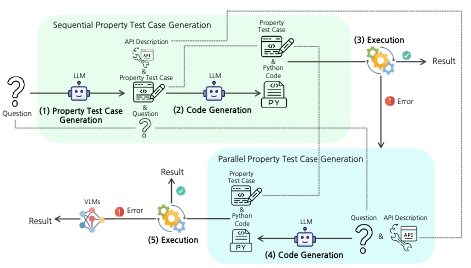
Forschende an der Rice University und der Columbia University haben eine Methode namens PropTest entwickelt, die die Zuverlässigkeit von KI-Systemen verbessert, die visuelle Schlussfolgerungsaufgaben durch das Schreiben von Computercode lösen. Diese "visuelle Programmierung"-Systeme funktionieren, indem sie große Sprachmodelle verwenden, um Python-Programme zu generieren, die Fragen zu Bildern beantworten, etwa das Identifizieren von Objekten oder das Beantworten mehrstufiger Fragen, aber sie produzieren häufig Code, der ohne Absturz läuft und dennoch aufgrund fehlerhafter Logik die falsche Antwort liefert. PropTest geht dies an, indem es eine alte Idee aus der Softwaretechnik übernimmt: Schreibe Tests, bevor du den Code schreibst. Konkret veranlasst das System zunächst ein Sprachmodell, kurze Testfälle zu generieren, die erwartete Eigenschaften der Antwort überprüfen — etwa zu verifizieren, dass das Ergebnis eine Zeichenkette ist, dass es ein oder zwei Wörter lang ist und dass es tatsächlich eine Art von Haushaltsgerät benennt, wenn die Frage nach Haushaltsgeräten fragt. Diese Tests werden dann als zusätzlicher Kontext in das Modell zurückgespeist, wenn der Haupt-Lösungscode generiert wird, was das Modell zu logisch korrekteren Programmen lenkt. Wenn der generierte Code diese Tests zur Laufzeit nicht besteht, greift das System auf ein standardmäßiges Vision-Language-Modell zurück, anstatt eine schlechte Antwort zurückzugeben. Getestet über vier Benchmarks hinweg, die visuelles Frage-Antworten und Objektlokalisierung abdecken, übertraf PropTest das Basis-System ViperGPT durchgängig über mehrere quelloffene Sprachmodelle hinweg, mit Gewinnen von bis zu 6 Prozentpunkten auf dem GQA-Datensatz und 8 Punkten auf RefCOCO+. Bemerkenswerterweise führten die Forschenden ihre Hauptexperimente mit frei verfügbaren Modellen wie CodeLlama und Llama3 statt mit proprietären APIs durch und adressierten damit ein Reproduzierbarkeitsproblem, das Vergleiche in diesem Forschungsbereich behindert hat.
Zusammenfassung
Visuelle Programmierung hat sich kürzlich als Alternative zu End-to-End-Blackbox-Modellen für visuelles Schlussfolgern herausgebildet. Diese Art von Methode nutzt Large Language Models (LLMs), um den Quellcode für ein ausführbares Computerprogramm zu generieren, das ein gegebenes Problem löst. Diese Strategie hat den Vorteil, einen interpretierbaren Schlussfolgerungspfad zu bieten, und erfordert kein Feinabstimmen eines Modells mit aufgabenspezifischen Daten. Wir schlagen PropTest vor, eine allgemeine Strategie, die die visuelle Programmierung weiter verbessert, indem ein LLM zusätzlich verwendet wird, um Code zu generieren, der in einer ersten Runde der vorgeschlagenen Lösungen visuelle Eigenschaften überprüft. Unsere Methode generiert Tests für die Konsistenz von Datentypen, die Ausgabesyntax und semantische Eigenschaften. PropTest erzielt vergleichbare Ergebnisse zu Methoden des Stands der Technik, während öffentlich verfügbare LLMs verwendet werden. Dies wird über verschiedene Benchmarks zum visuellen Frage-Antworten und zum Verständnis referenzierender Ausdrücke hinweg demonstriert. Insbesondere verbessert PropTest ViperGPT, indem es 46,1 % Genauigkeit (+6,0 %) auf GQA mit Llama3-8B und 59,5 % (+8,1 %) auf RefCOCO+ mit CodeLlama-34B erreicht.
Details
Zitation
@inproceedings{koo2024proptest,
title = {PropTest: Automatic Property Testing for Improved Visual Programming},
author = {Koo, Jaywon and Yang, Ziyan and Cascante-Bonilla, Paola and Ray, Baishakhi and Ordonez, Vicente},
year = {2024},
booktitle = {Conf. on Empirical Methods in Natural Language Processing. EMNLP 2024},
url = {https://arxiv.org/abs/2403.16921},
}
automatisch generierte Fragen, wichtigste Beiträge und Grenzen dieses Artikels
Fragen, die dieser Artikel beantworten hilft
- Was ist PropTest? PropTest ist ein Framework für visuelle Programmierung, das ein LLM verwendet, um Eigenschaftstests zu generieren, bevor ausführbarer Code für visuelle Schlussfolgerungsaufgaben generiert wird.
- Welches Problem adressiert PropTest? Es zielt auf Fälle ab, in denen generierte visuelle Programme ohne Syntax- oder Laufzeitfehler laufen, aber dennoch logisch falsche Antworten zurückgeben.
- Wie verbessern Eigenschaftstests die visuelle Programmierung? Die Tests kodieren erwartete Antworteigenschaften wie Datentyp, Ausgabeformat, semantische Kategorie oder visuelle Attribute, lenken dann die Codegenerierung und helfen, ungültige Ausgaben zu erkennen.
- Welche Aufgaben bewertet die Arbeit? Die Arbeit bewertet visuelles Frage-Antworten auf GQA und A-OKVQA sowie visuelles Grounding auf RefCOCO und RefCOCO+.
- Warum ist die Verwendung quelloffener LLMs wichtig? Die Arbeit betont reproduzierbare Experimente zur visuellen Programmierung mit Modellen wie Llama3 und CodeLlama und verringert so die Abhängigkeit von geschlossenen oder veralteten API-Modellen.
Wichtigste Beiträge
- Die Arbeit führt die automatische Generierung von Eigenschaftstests als allgemeinen Mechanismus zur Verbesserung von LLM-generierten visuellen Programmen ein.
- PropTest unterstützt sowohl Aufgaben mit Textantworten als auch Grounding-Aufgaben mit Begrenzungsrahmen, indem es Tests generiert, die auf den erwarteten Ausgabetyp zugeschnitten sind.
- Die Methode verbessert ViperGPT über mehrere Benchmarks und LLM-Backbones hinweg, einschließlich berichteter Gewinne von +6,0 % auf GQA mit Llama3-8B und +8,1 % auf RefCOCO+ mit CodeLlama-34B.
- Die Arbeit zeigt, dass generierte Tests die Codequalität verbessern können, anstatt lediglich die Abhängigkeit von Fallback-Vision-Language-Modellen zu erhöhen.
- Die Arbeit liefert ein besser reproduzierbares Bewertungsszenario für die visuelle Programmierung, indem sie sich auf öffentlich verfügbare LLMs und einen API-freien Implementierungspfad konzentriert.
Grenzen und Vorbehalte
- PropTest fügt einen zusätzlichen LLM-Aufruf zur Generierung von Eigenschaftstests hinzu, aber dies ist ein praktischer Kompromiss für zuverlässigere visuelle Programme und sollte günstiger werden, wenn schnellere Code-Modelle besser werden.
- Verschiedene Ausgabetypen erfordern verschiedene Prompts für Eigenschaftstests, was die Implementierung explizit hält und zugleich auf eine klare zukünftige Richtung verweist: das automatische Entwerfen von Prompts je nach Aufgabe.
- Generierte Eigenschaftstests können selbst Fehler enthalten, aber die Arbeit analysiert dieses Verhalten und zeigt, dass die Tests in der Regel genau genug sind, um die End-to-End-Ergebnisse zu verbessern.
- Das Framework hängt nach wie vor von der Qualität der visuellen Werkzeuge und APIs ab, die von den generierten Programmen verwendet werden, was es zu einer Ergänzung von Arbeiten zu besserer Werkzeugkonstruktion und Selbstverfeinerung macht.
- Die Bewertung konzentriert sich auf bildbasiertes VQA und das Verständnis referenzierender Ausdrücke und lässt video-, zeit- und kausalbezogenes visuelles Schlussfolgern als vielversprechende nächste Anwendungen offen.
Wie dieses Ergebnis zu lesen ist
Diese Arbeit lässt sich am besten als ein starker und praktischer Schritt hin zu zuverlässigerer visueller Programmierung lesen: PropTest bringt Ideen des Softwaretests in das multimodale Schlussfolgern ein, verbessert die Logik der generierten Programme über Benchmarks hinweg und tut dies in einem reproduzierbaren Szenario mit öffentlichen LLMs.