PropTest: Automatic Property Testing for Improved Visual Programming
Sintesi del comunicato stampa
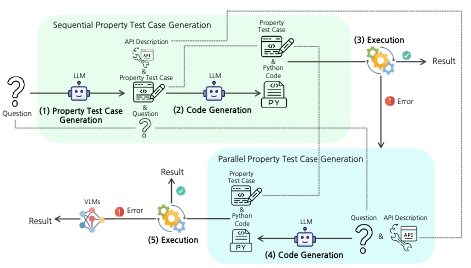
I ricercatori della Rice University e della Columbia University hanno sviluppato un metodo chiamato PropTest che migliora l'affidabilità dei sistemi di IA che risolvono compiti di ragionamento visivo scrivendo codice informatico. Questi sistemi di "visual programming" funzionano utilizzando grandi modelli linguistici per generare programmi Python che rispondono a domande sulle immagini, come l'identificazione di oggetti o la risposta a domande in più passaggi, ma producono frequentemente codice che viene eseguito senza bloccarsi pur fornendo comunque la risposta sbagliata a causa di una logica difettosa. PropTest affronta questo problema prendendo in prestito una vecchia idea dell'ingegneria del software: scrivere i test prima di scrivere il codice. Nello specifico, il sistema chiede prima a un modello linguistico di generare brevi casi di test che verificano le proprietà attese della risposta, ad esempio controllando che il risultato sia una stringa, che sia lungo una o due parole e che nomini effettivamente un tipo di elettrodomestico quando la domanda riguarda gli elettrodomestici. Questi test vengono poi reimmessi nel modello come contesto aggiuntivo durante la generazione del codice della soluzione principale, orientando il modello verso programmi logicamente più corretti. Quando il codice generato non supera questi test in fase di esecuzione, il sistema ricorre a un modello vision-language standard invece di restituire una risposta errata. Testato su quattro benchmark che coprono il visual question answering e la localizzazione di oggetti, PropTest ha superato costantemente il sistema di riferimento ViperGPT su molteplici modelli linguistici open-source, con guadagni fino a 6 punti percentuali sul dataset GQA e 8 punti su RefCOCO+. È degno di nota il fatto che i ricercatori abbiano condotto i loro esperimenti principali utilizzando modelli liberamente disponibili come CodeLlama e Llama3 anziché API proprietarie, affrontando un problema di riproducibilità che ha ostacolato i confronti in quest'area di ricerca.
abstract
Il Visual Programming è emerso recentemente come alternativa ai modelli di ragionamento visivo end-to-end di tipo black-box. Questo tipo di metodo sfrutta i Large Language Models (LLM) per generare il codice sorgente di un programma eseguibile che risolve un dato problema. Questa strategia ha il vantaggio di offrire un percorso di ragionamento interpretabile e non richiede il finetuning di un modello con dati specifici per il task. Proponiamo PropTest, una strategia generale che migliora il visual programming utilizzando ulteriormente un LLM per generare codice che verifica le proprietà visive in un primo round di soluzioni proposte. Il nostro metodo genera test per la coerenza dei tipi di dato, la sintassi dell'output e le proprietà semantiche. PropTest ottiene risultati comparabili ai metodi allo stato dell'arte pur utilizzando LLM disponibili pubblicamente. Ciò viene dimostrato su diversi benchmark di visual question answering e referring expression comprehension. In particolare, PropTest migliora ViperGPT ottenendo un'accuratezza del 46.1\% (+6.0\%) su GQA usando Llama3-8B e del 59.5\% (+8.1\%) su RefCOCO+ usando CodeLlama-34B.
dettagli
citazione
@inproceedings{koo2024proptest,
title = {PropTest: Automatic Property Testing for Improved Visual Programming},
author = {Koo, Jaywon and Yang, Ziyan and Cascante-Bonilla, Paola and Ray, Baishakhi and Ordonez, Vicente},
year = {2024},
booktitle = {Conf. on Empirical Methods in Natural Language Processing. EMNLP 2024},
url = {https://arxiv.org/abs/2403.16921},
}
domande, principali contributi e limiti di questo articolo generati automaticamente
Domande a cui questo articolo aiuta a rispondere
- Che cos'è PropTest? PropTest è un framework di visual programming che utilizza un LLM per generare test sulle proprietà prima di generare il codice eseguibile per compiti di ragionamento visivo.
- Quale problema affronta PropTest? Si rivolge ai casi in cui i programmi visivi generati vengono eseguiti senza errori di sintassi o di runtime ma restituiscono comunque risposte logicamente errate.
- In che modo i test sulle proprietà migliorano il visual programming? I test codificano le proprietà attese della risposta, come il tipo di dato, il formato dell'output, la categoria semantica o gli attributi visivi, e in seguito guidano la generazione del codice e aiutano a rilevare gli output non validi.
- Quali task valuta il paper? Il paper valuta il visual question answering su GQA e A-OKVQA, e il visual grounding su RefCOCO e RefCOCO+.
- Perché è importante l'uso di LLM open-source? Il paper pone l'accento su esperimenti di visual programming riproducibili utilizzando modelli come Llama3 e CodeLlama, riducendo la dipendenza da modelli API chiusi o deprecati.
Principali contributi
- Il paper introduce la generazione automatica di test sulle proprietà come meccanismo generale per migliorare i programmi visivi generati dagli LLM.
- PropTest supporta sia i task con risposta testuale sia i task di grounding con bounding-box, generando test su misura per il tipo di output atteso.
- Il metodo migliora ViperGPT su molteplici benchmark e backbone LLM, inclusi i guadagni riportati di +6.0% su GQA con Llama3-8B e +8.1% su RefCOCO+ con CodeLlama-34B.
- Il lavoro mostra che i test generati possono migliorare la qualità del codice anziché aumentare semplicemente il ricorso ai modelli vision-language di fallback.
- Il paper contribuisce a un contesto di valutazione più riproducibile per il visual programming concentrandosi su LLM disponibili pubblicamente e su un percorso di implementazione privo di API.
Limiti e avvertenze
- PropTest aggiunge una chiamata LLM in più per generare i test sulle proprietà, ma si tratta di un compromesso pratico per ottenere programmi visivi più affidabili e dovrebbe diventare meno costoso man mano che i modelli di codice più veloci migliorano.
- Tipi di output diversi richiedono prompt di test sulle proprietà diversi, il che mantiene l'implementazione esplicita e indica anche una chiara direzione futura: progettare automaticamente i prompt in base al task.
- I test sulle proprietà generati possono a loro volta contenere errori, ma il paper analizza questo comportamento e mostra che i test sono di solito sufficientemente accurati da migliorare i risultati end-to-end.
- Il framework dipende ancora dalla qualità degli strumenti visivi e delle API utilizzati dai programmi generati, rendendolo complementare al lavoro sulla costruzione di strumenti migliori e sull'auto-raffinamento.
- La valutazione si concentra sul VQA basato su immagini e sulla referring expression comprehension, lasciando il ragionamento visivo su video, temporale e causale come promettenti applicazioni successive.
Come interpretare questo risultato
Questo paper si legge al meglio come un passo solido e pratico verso un visual programming più affidabile: PropTest porta le idee del testing del software nel ragionamento multimodale, migliora la logica dei programmi generati su diversi benchmark e lo fa in un contesto riproducibile con LLM pubblici.