Chair Segments: A Compact Benchmark for the Study of Object Segmentation
Zusammenfassung der Pressemitteilung
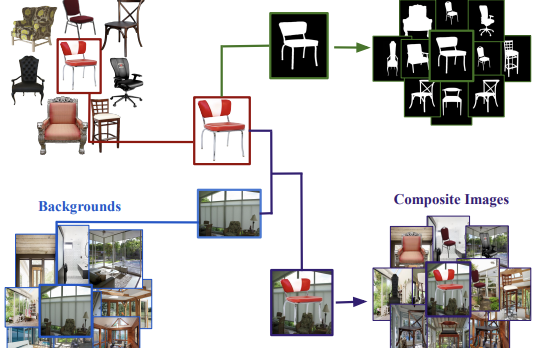
Forscher der University of Virginia und kooperierender Institutionen haben einen neuen Datensatz namens Chair Segments veröffentlicht, der Wissenschaftlern im Bereich des maschinellen Sehens eine schnellere und günstigere Möglichkeit bieten soll, Algorithmen zur Bildsegmentierung zu testen. Das Kernproblem, das sie identifizierten, besteht darin, dass bestehende Segmentierungsdatensätze — wie COCO oder PASCAL VOC — groß und teuer zu annotieren sind und Modelle dazu zwingen, gleichzeitig Objekterkennung, Lokalisierung und Maskierung auf Pixelebene zu bewältigen, was es erschwert, segmentierungsspezifische Ideen zu isolieren und schnell zu iterieren. Um dies zu umgehen, baute das Team einen halbsynthetischen Datensatz aus rund 900 Stuhlbildern mit transparenten Hintergründen, die auf 10.000 vielfältige Innen- und Außenszenenbilder montiert wurden, wodurch 50.000 Trainingskomposite mit pixelgenauen Ground-Truth-Masken entstanden, die keine manuelle Annotation erforderten. Die Forscher wählten Stühle bewusst: Die Kategorie ist aufgrund dünner, hohler und sich selbst verdeckender Teile notorisch schwer zu segmentieren und zählt zu den schwierigsten in bestehenden Benchmarks. Ihre Experimente zeigten, dass ein U-Net-Modell auf dem Datensatz bei einer Auflösung von 64×64 in etwa 30 Minuten auf einer einzigen GPU bis zur vollständigen Konvergenz trainiert werden kann — ungefähr auf dem Komplexitätsniveau von CIFAR-10 für die Klassifikation — und dabei dennoch sinnvoll zwischen stärkeren und schwächeren Architekturen unterscheidet. Wichtig ist, dass Modelle, die auf Chair Segments vortrainiert und anschließend auf dem nicht verwandten Object Discovery-Datensatz (der Autos, Pferde und Flugzeuge umfasst) verfeinert wurden, alle zuvor veröffentlichten Methoden auf diesem Benchmark übertrafen, was darauf hindeutet, dass die halbsynthetischen Daten tatsächlich nützliche reale Merkmale erfassen. Das Team bestätigte außerdem zum ersten Mal in der Segmentierung ein zuvor in der Bildklassifikation beobachtetes Muster: Modelle, die aus denselben vortrainierten Gewichten verfeinert wurden, gruppieren sich in der Optimierungslandschaft zusammen und gehen reibungslos ineinander über, während Modelle, die aus zufälliger Initialisierung trainiert wurden, dies nicht tun — eine Erkenntnis mit praktischen Implikationen dafür, wie Segmentierungsmodelle initialisiert und zu Ensembles zusammengefasst werden könnten.
Zusammenfassung
Im Laufe der Jahre haben Datensätze und Benchmarks einen überproportionalen Einfluss auf den Entwurf neuartiger Algorithmen gehabt. In dieser Arbeit stellen wir ChairSegments vor, einen neuartigen und kompakten halbsynthetischen Datensatz für die Objektsegmentierung. Wir zeigen außerdem empirische Erkenntnisse im Transfer Learning, die jüngste Erkenntnisse für die Bildklassifikation widerspiegeln. Insbesondere zeigen wir, dass Modelle, die aus einer vortrainierten Menge von Gewichten verfeinert werden, im selben Becken der Optimierungslandschaft liegen. ChairSegments besteht aus einer vielfältigen Menge prototypischer Bilder von Stühlen mit transparenten Hintergründen, die in eine vielfältige Auswahl von Hintergründen eingefügt sind. Unser Ziel ist es, dass ChairSegments das Äquivalent zum CIFAR-10-Datensatz ist, jedoch für das schnelle Entwerfen und Iterieren über neuartige Modellarchitekturen für die Segmentierung. Auf Chair Segments kann ein U-Net-Modell mit einer einzigen GPU in nur dreißig Minuten bis zur vollständigen Konvergenz trainiert werden. Schließlich kann dieser Datensatz, obwohl er halbsynthetisch ist, ein nützlicher Ersatz für reale Daten sein und zu einer Genauigkeit auf dem Stand der Technik auf dem Object Discovery-Datensatz führen, wenn er als Quelle für das Vortraining verwendet wird.
Details
Zitation
@article{pintoalva2011chair,
title = {Chair Segments: A Compact Benchmark for the Study of Object Segmentation},
author = {Pinto-Alva, Leticia and Torres, Ian K. and Garcia, Rosangel and Yang, Ziyan and Ordonez, Vicente},
year = {2011},
journal = {arxiv:2011.14027 Nov 2020.},
url = {https://arxiv.org/abs/2012.01250},
}