Chair Segments: A Compact Benchmark for the Study of Object Segmentation
Краткое изложение пресс-релиза
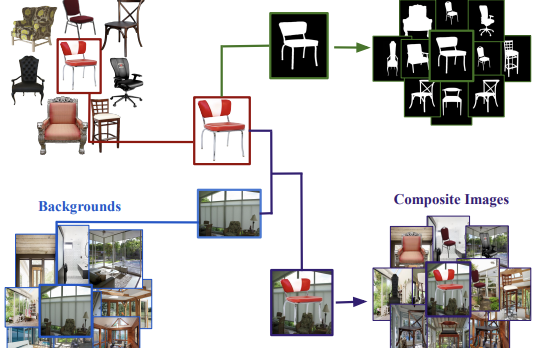
Исследователи из University of Virginia и сотрудничающих институтов выпустили новый набор данных под названием Chair Segments, призванный дать учёным в области компьютерного зрения более быстрый и дешёвый способ тестирования алгоритмов сегментации изображений. Основная проблема, которую они выявили, заключается в том, что существующие наборы данных для сегментации — такие как COCO или PASCAL VOC — большие, дорогие в аннотировании и вынуждают модели одновременно справляться с распознаванием объектов, локализацией и попиксельным маскированием, что затрудняет изоляцию и быстрое итерирование идей, специфичных для сегментации. Чтобы обойти это, команда построила полусинтетический набор данных из примерно 900 изображений стульев с прозрачным фоном, скомпонованных на 10 000 разнообразных изображений сцен в помещении и на улице, произведя 50 000 обучающих композитов с попиксельно точными эталонными масками, которые не требовали ручного аннотирования. Исследователи выбрали стулья намеренно: эта категория общеизвестно сложна для сегментации из-за тонких, полых и самозаслоняющихся частей, и она входит в число самых сложных в существующих бенчмарках. Их эксперименты показали, что модель U-Net можно обучить до полной сходимости на этом наборе данных примерно за 30 минут на одном GPU при разрешении 64×64 — примерно уровень сложности CIFAR-10 для классификации — при этом по-прежнему значимо различая более сильные и более слабые архитектуры. Важно, что модели, предобученные на Chair Segments и затем дообученные на несвязанном наборе данных Object Discovery (охватывающем автомобили, лошадей и самолёты), превзошли все ранее опубликованные методы на этом бенчмарке, что говорит о том, что полусинтетические данные улавливают действительно полезные реальные признаки. Команда также подтвердила, впервые в сегментации, паттерн, ранее наблюдавшийся в классификации изображений: модели, дообученные из одних и тех же предобученных весов, группируются вместе в ландшафте оптимизации и плавно переходят одна в другую, тогда как модели, обученные из случайной инициализации, — нет, и это находка с практическими последствиями для того, как могли бы инициализироваться и ансамблироваться модели сегментации.
аннотация
На протяжении многих лет наборы данных и бенчмарки оказывали непропорционально большое влияние на проектирование новых алгоритмов. В этой статье мы представляем ChairSegments — новый и компактный полусинтетический набор данных для сегментации объектов. Мы также показываем эмпирические находки в transfer learning, которые отражают недавние находки для классификации изображений. В частности, мы показываем, что модели, дообученные из предобученного набора весов, лежат в одном и том же бассейне ландшафта оптимизации. ChairSegments состоит из разнообразного набора прототипических изображений стульев с прозрачным фоном, скомпонованных в разнообразный массив фонов. Мы стремимся к тому, чтобы ChairSegments стал эквивалентом набора данных CIFAR-10, но для быстрого проектирования и итерирования новых архитектур моделей для сегментации. На Chair Segments модель U-Net можно обучить до полной сходимости всего за тридцать минут на одном GPU. Наконец, хотя этот набор данных является полусинтетическим, он может быть полезным заместителем реальных данных, приводя к точности на современном уровне на наборе данных Object Discovery при использовании в качестве источника предобучения.
подробности
цитирование
@article{pintoalva2011chair,
title = {Chair Segments: A Compact Benchmark for the Study of Object Segmentation},
author = {Pinto-Alva, Leticia and Torres, Ian K. and Garcia, Rosangel and Yang, Ziyan and Ordonez, Vicente},
year = {2011},
journal = {arxiv:2011.14027 Nov 2020.},
url = {https://arxiv.org/abs/2012.01250},
}