Chat-crowd: A Dialog-based Platform for Visual Layout Composition
Résumé du communiqué de presse
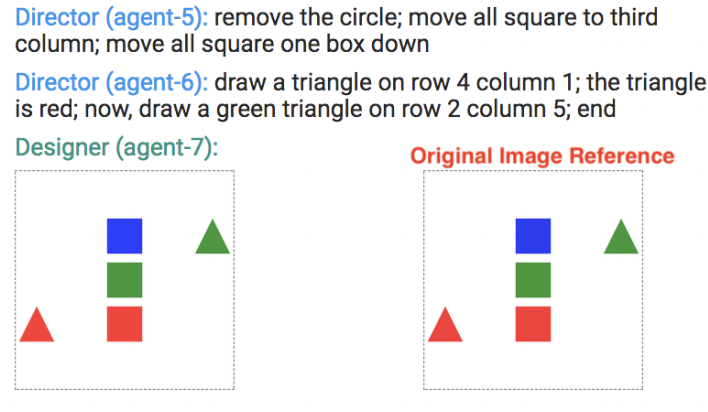
Des chercheurs de l'Université de Virginie et d'IBM ont construit un outil de collecte de données baptisé Chat-crowd qui permet à des paires de travailleurs humains de reconstituer des mises en page visuelles par une conversation en va-et-vient, dans le but de générer des données d'entraînement pour les systèmes d'IA qui doivent comprendre le langage spatial. Le dispositif attribue à un travailleur le rôle de « directeur », qui peut voir une image de référence contenant des formes ou des objets du monde réel, et à un autre celui de « concepteur », qui manipule un canevas modifiable en se fondant uniquement sur les instructions textuelles du directeur. Un choix d'ingénierie notable est que les deux travailleurs n'ont pas besoin d'être connectés simultanément — des personnes différentes peuvent reprendre l'un ou l'autre rôle en cours de conversation, ce qui réduit le coût et la complexité de la collecte de données par crowdsourcing. Le système injecte également des messages synthétiques émis par un robot afin de provoquer des actions conversationnelles moins courantes, comme les questions de clarification, et utilise ces injections pour évaluer discrètement la qualité des travailleurs. En testant la plateforme sur de simples mises en page de formes géométriques et des agencements d'objets issus du jeu de données d'images COCO, les chercheurs ont constaté que les directeurs décrivaient de manière fiable les objets par leur emplacement, leur couleur et leur forme dans plus de 90 pour cent des instructions, tandis que les concepteurs ne posaient des questions de clarification qu'environ 40 pour cent du temps et se contentaient généralement de modifier directement le canevas. Les scènes plus complexes — celles comportant six à huit objets — nécessitaient plus du double de tours de conversation pour être achevées par rapport aux plus simples, ce qui souligne combien la complexité de la scène accroît la demande linguistique. Ce travail est important parce que les jeux de données associant langage naturel et raisonnement spatial restent rares, et Chat-crowd offre un moyen pratique et évolutif de les produire pour entraîner les futurs systèmes d'IA vision-langage.
résumé
Dans cet article, nous présentons Chat-crowd, un environnement interactif de composition de mises en page visuelles par interactions conversationnelles. Chat-crowd prend en charge plusieurs agents jouant deux rôles conversationnels : les agents qui tiennent le rôle de concepteur sont chargés de placer des objets sur un canevas modifiable selon les instructions ou les commandes émises par des agents jouant le rôle de directeur. Le système peut être intégré à des plateformes de crowdsourcing pour la collecte de données aussi bien synchrone qu'asynchrone, et est doté de contrôles qualité complets portant sur les performances des deux types d'agents. Nous espérons que ce système sera utile pour construire des tâches de dialogue multimodal orientées vers un objectif et nécessitant un raisonnement spatial et géométrique.
citation
@inproceedings{cascantebonilla2019chat,
title = {Chat-crowd: A Dialog-based Platform for Visual Layout Composition},
author = {Cascante-Bonilla, Paola and Yin, Xuwang and Ordonez, Vicente and Feng, Song},
year = {2019},
booktitle = {North American Chapter of the Association for Computational Linguistics. NAACL 2019},
url = {https://chatcrowd.github.io/},
}