Chat-crowd: A Dialog-based Platform for Visual Layout Composition
新闻稿摘要
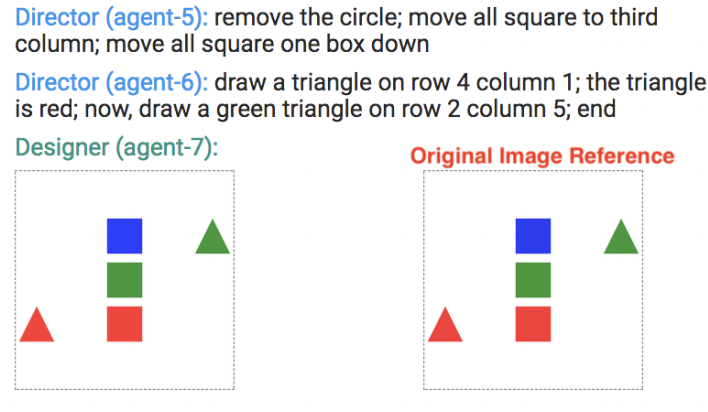
弗吉尼亚大学和 IBM 的研究人员构建了一个名为 Chat-crowd 的数据收集工具,它让成对的人类工作者通过往返对话来重建视觉布局,目标是为需要理解空间语言的 AI 系统生成训练数据。该设置将一名工作者指定为“指挥者”角色,他可以看到一张包含形状或现实世界物体的参考图像,另一名作为“设计师”,仅根据指挥者的文本指令操作可编辑的画布。一个值得注意的工程选择是,两名工作者不需要同时在线——不同的人可以在对话进行到一半时接手任一角色,这降低了众包数据收集的成本和复杂性。该系统还注入来自机器人的合成消息,以引发较不常见的对话行为,例如澄清性问题,并利用这些注入来悄悄评估工作者的质量。研究人员在简单的几何形状布局以及来自 COCO 图像数据集的物体排列上测试了该平台,发现指挥者在超过 90% 的指令中可靠地使用位置、颜色和形状来描述物体,而设计师仅在约 40% 的情况下提出澄清性问题,通常只是直接修改画布。更复杂的场景——那些有六到八个物体的场景——完成所需的对话轮次是较简单场景的两倍多,凸显了场景复杂度如何驱动语言需求。这项工作之所以重要,是因为将自然语言与空间推理配对的数据集仍然稀缺,而 Chat-crowd 为生成这类数据以训练未来的视觉-语言 AI 系统提供了一种实用、可扩展的方法。
摘要
在本文中,我们介绍 Chat-crowd,这是一个通过对话交互进行视觉布局构图的交互式环境。Chat-crowd 支持多个具有两种对话角色的智能体:扮演设计师角色的智能体负责根据扮演指挥者角色的智能体发出的指令或命令,在可编辑的画布上放置物体。该系统可以与众包平台集成,用于同步和异步数据收集,并配备了对两类智能体表现的全面质量控制。我们期望该系统将有助于构建需要空间和几何推理的多模态目标导向对话任务。
引用
@inproceedings{cascantebonilla2019chat,
title = {Chat-crowd: A Dialog-based Platform for Visual Layout Composition},
author = {Cascante-Bonilla, Paola and Yin, Xuwang and Ordonez, Vicente and Feng, Song},
year = {2019},
booktitle = {North American Chapter of the Association for Computational Linguistics. NAACL 2019},
url = {https://chatcrowd.github.io/},
}