General Multi-label Image Classification with Transformers
Resumen de prensa
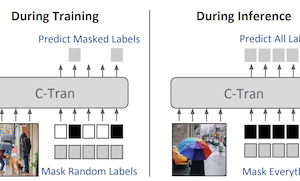
Investigadores de la Universidad de Virginia han desarrollado un nuevo sistema de aprendizaje profundo, llamado Classification Transformer (C-Tran), que mejora la capacidad de una computadora para identificar simultáneamente múltiples objetos o conceptos dentro de una sola imagen, una tarea conocida como clasificación de imágenes con múltiples etiquetas. A diferencia de la mayoría de los enfoques existentes, que tratan cada predicción de etiqueta en gran medida de forma aislada o dependen de grafos de conocimiento predefinidos para capturar las relaciones entre etiquetas, C-Tran introduce conjuntamente tanto las características de la imagen como la información de las etiquetas en un codificador Transformer, el mismo tipo de arquitectura que ha impulsado los avances recientes en el procesamiento del lenguaje natural. La innovación clave es un procedimiento de entrenamiento llamado Label Mask Training, en el que el modelo aprende a predecir etiquetas ocultas aleatoriamente dado un conocimiento parcial de las demás, de forma muy parecida a los ejercicios de completar espacios en blanco usados para entrenar modelos de lenguaje como BERT. Este enfoque enseña al sistema a comprender cómo se relacionan las etiquetas entre sí —por ejemplo, que un tenedor y un cuchillo tienden a aparecer juntos— sin necesidad de reglas hechas a mano. Más allá de la clasificación estándar, C-Tran también puede aceptar información parcial de etiquetas en el momento de la inferencia, lo que significa que un usuario puede indicarle al modelo que ciertas etiquetas están definitivamente presentes o ausentes y recibir predicciones más precisas para las desconocidas restantes. El sistema logró resultados de vanguardia en conjuntos de datos de referencia como Microsoft COCO y Visual Genome, y también superó a los métodos competidores cuando se probó con etiquetas parcialmente conocidas o complementarias en cuatro conjuntos de datos. La importancia práctica es que las imágenes del mundo real a menudo vienen con metadatos incompletos o contextuales —como etiquetas de ubicación o pies de foto— y C-Tran es el primer modelo diseñado para explotar de forma flexible ese tipo de evidencia parcial dentro de un único marco unificado.
resumen
La clasificación de imágenes con múltiples etiquetas es la tarea de predecir un conjunto de etiquetas correspondientes a objetos, atributos u otras entidades presentes en una imagen. En este trabajo proponemos el Classification Transformer (C-Tran), un marco general para la clasificación de imágenes con múltiples etiquetas que aprovecha los Transformers para explotar las complejas dependencias entre las características visuales y las etiquetas. Nuestro enfoque consiste en un codificador Transformer entrenado para predecir un conjunto de etiquetas objetivo dado un conjunto de entrada de etiquetas enmascaradas y características visuales de una red neuronal convolucional. Un ingrediente clave de nuestro método es un objetivo de entrenamiento de enmascaramiento de etiquetas que usa un esquema de codificación ternario para representar el estado de las etiquetas como positivo, negativo o desconocido durante el entrenamiento. Nuestro modelo muestra un rendimiento de vanguardia en conjuntos de datos desafiantes como COCO y Visual Genome. Además, debido a que nuestro modelo representa explícitamente la incertidumbre de las etiquetas durante el entrenamiento, es más general al permitirnos producir mejores resultados para imágenes con anotaciones de etiquetas parciales o adicionales durante la inferencia. Demostramos esta capacidad adicional en los conjuntos de datos de imágenes COCO, Visual Genome, News500 y CUB.
detalles
cita
@inproceedings{lanchantin2021general,
title = {General Multi-label Image Classification with Transformers},
author = {Lanchantin, Jack and Wang, Tianlu and Ordonez, Vicente and Qi, Yanjun},
year = {2021},
booktitle = {Conference on Computer Vision and Pattern Recognition CVPR 2021},
url = {https://arxiv.org/abs/2011.14027},
}