Esta demo intenta resaltar zonas de una imagen condicionadas por un texto de entrada arbitrario.
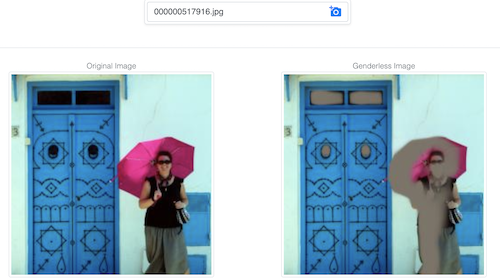
Esta demo intenta dificultar que un modelo prediga el género a partir de una imagen, modificándola para que esa tarea sea más difícil sin perder la mayor parte de la información de la imagen.
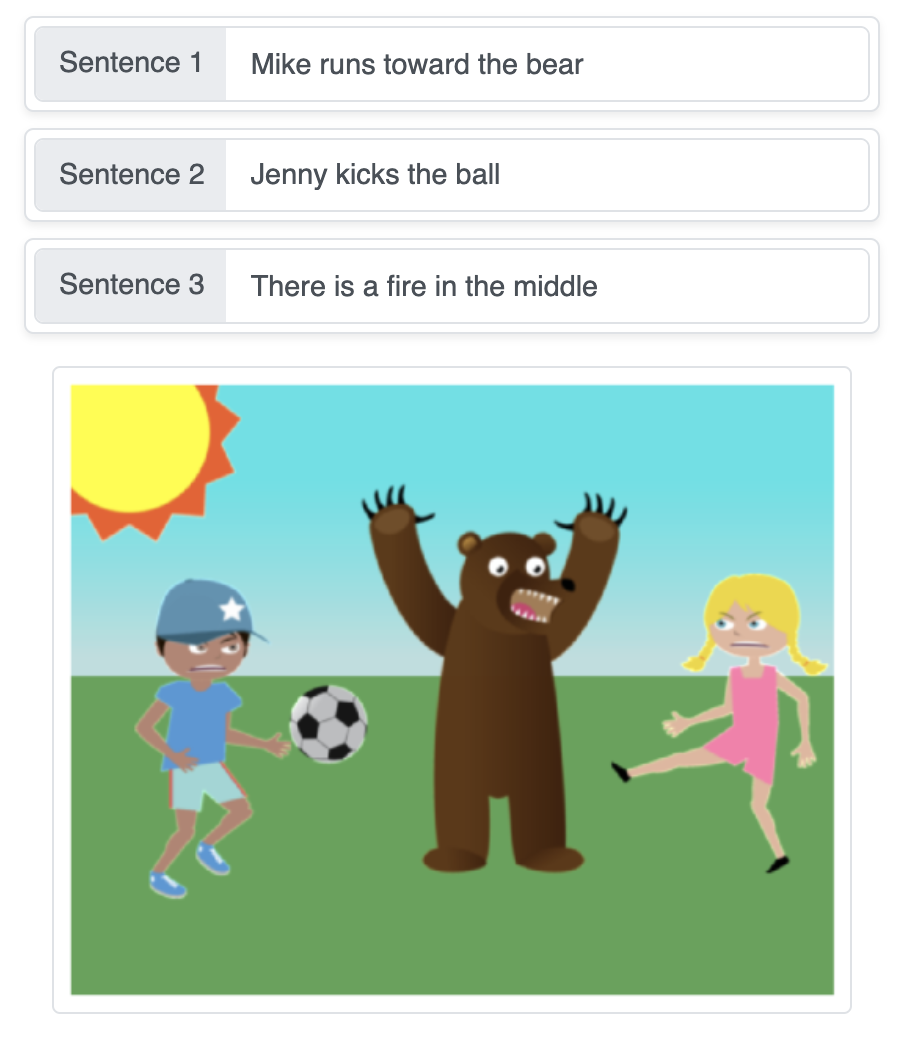
Esta demo convierte descripciones textuales en una escena generada automáticamente, colocando objetos de forma secuencial sobre un fondo liso, paso a paso, mediante redes neuronales de generación de secuencias.
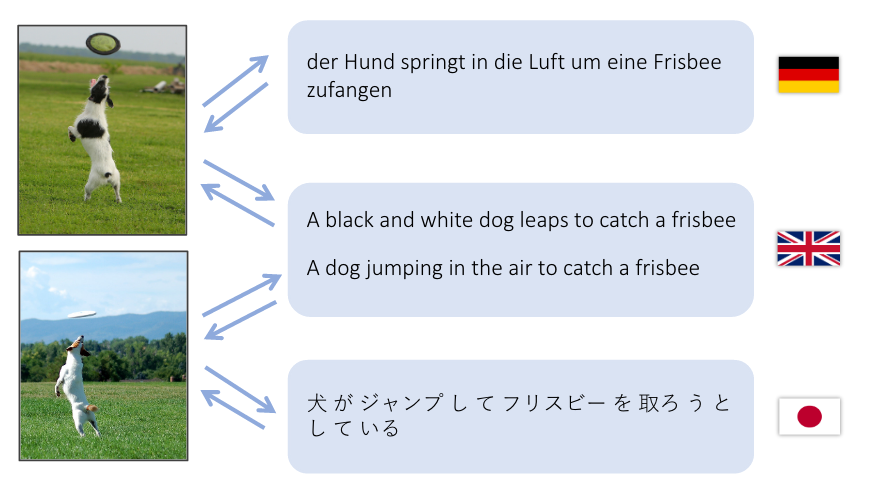
Esta demo intenta traducir una frase en inglés a un espacio de características visuales y a una frase tanto en alemán (Deutsch) como en japonés (日本語).
Busca imágenes por texto en el conjunto de datos SBU Captions, que tiene 1 millón de imágenes con descripciones de Flickr y se ha usado en numerosos proyectos.
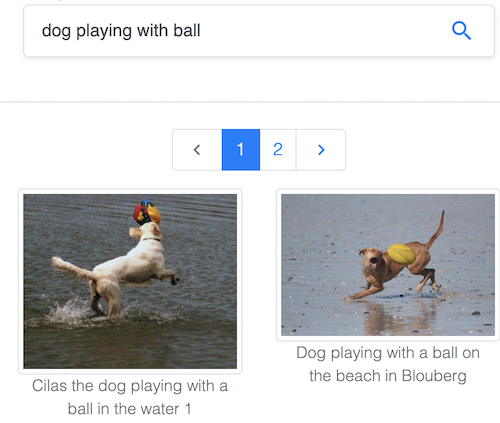
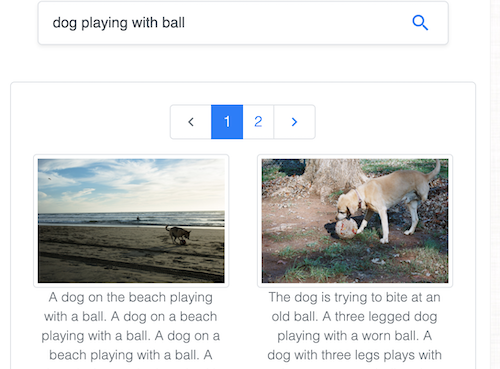
Busca imágenes por texto en el popular conjunto de datos Common Objects in Context (COCO), mantenido por la Common Visual Data Foundation.