General Multi-label Image Classification with Transformers
Résumé du communiqué de presse
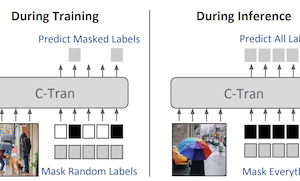
Des chercheurs de l'université de Virginie ont mis au point un nouveau système d'apprentissage profond, appelé Classification Transformer (C-Tran), qui améliore la capacité d'un ordinateur à identifier simultanément plusieurs objets ou concepts au sein d'une même image — une tâche connue sous le nom de classification d'images multi-étiquettes. Contrairement à la plupart des approches existantes, qui traitent chaque prédiction d'étiquette largement de manière isolée ou s'appuient sur des graphes de connaissances prédéfinis pour capturer les relations entre étiquettes, C-Tran introduit conjointement les caractéristiques de l'image et les informations d'étiquettes dans un encodeur Transformer, le même type d'architecture qui a porté les récentes avancées du traitement du langage naturel. L'innovation clé est une procédure d'entraînement appelée Label Mask Training, dans laquelle le modèle apprend à prédire des étiquettes masquées aléatoirement à partir d'une connaissance partielle des autres, à la manière des exercices à trous utilisés pour entraîner des modèles de langage tels que BERT. Cette approche apprend au système à comprendre comment les étiquettes se rapportent les unes aux autres — par exemple, qu'une fourchette et un couteau ont tendance à apparaître ensemble — sans nécessiter de règles élaborées à la main. Au-delà de la classification standard, C-Tran peut aussi accepter des informations d'étiquettes partielles au moment de l'inférence, ce qui signifie qu'un utilisateur peut indiquer au modèle que certaines étiquettes sont définitivement présentes ou absentes et recevoir des prédictions plus précises pour les inconnues restantes. Le système a obtenu des résultats à l'état de l'art sur des jeux de données de référence dont Microsoft COCO et Visual Genome, et a également surpassé les méthodes concurrentes lorsqu'il a été testé avec des étiquettes partiellement connues ou supplémentaires sur quatre jeux de données. Son intérêt pratique tient au fait que les images du monde réel s'accompagnent souvent de métadonnées incomplètes ou contextuelles — comme des balises de localisation ou des légendes — et que C-Tran est le premier modèle conçu pour exploiter de manière souple ce type de preuve partielle au sein d'un cadre unifié unique.
résumé
La classification d'images multi-étiquettes consiste à prédire un ensemble d'étiquettes correspondant aux objets, attributs ou autres entités présents dans une image. Dans ce travail, nous proposons le Classification Transformer (C-Tran), un cadre général de classification d'images multi-étiquettes qui s'appuie sur les Transformers pour exploiter les dépendances complexes entre les caractéristiques visuelles et les étiquettes. Notre approche repose sur un encodeur Transformer entraîné à prédire un ensemble d'étiquettes cibles à partir d'un ensemble d'étiquettes masquées en entrée et de caractéristiques visuelles issues d'un réseau de neurones convolutif. Un ingrédient clé de notre méthode est un objectif d'entraînement par masquage d'étiquettes qui utilise un schéma de codage ternaire pour représenter l'état des étiquettes comme positif, négatif ou inconnu durant l'entraînement. Notre modèle obtient des performances à l'état de l'art sur des jeux de données exigeants tels que COCO et Visual Genome. De plus, parce que notre modèle représente explicitement l'incertitude des étiquettes durant l'entraînement, il est plus général en nous permettant de produire des résultats améliorés pour des images comportant des annotations d'étiquettes partielles ou supplémentaires lors de l'inférence. Nous démontrons cette capacité additionnelle sur les jeux de données d'images COCO, Visual Genome, News500 et CUB.
détails
citation
@inproceedings{lanchantin2021general,
title = {General Multi-label Image Classification with Transformers},
author = {Lanchantin, Jack and Wang, Tianlu and Ordonez, Vicente and Qi, Yanjun},
year = {2021},
booktitle = {Conference on Computer Vision and Pattern Recognition CVPR 2021},
url = {https://arxiv.org/abs/2011.14027},
}