Feedback-prop: Convolutional Neural Network Inference under Partial Evidence
Résumé du communiqué de presse
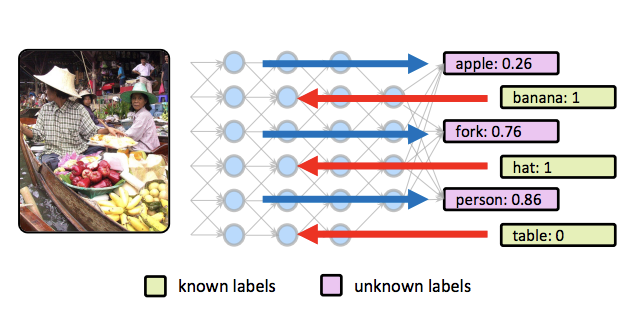
Des chercheurs de l'Université de Virginie et de CyberAgent ont mis au point une technique qui permet aux réseaux de neurones existants de reconnaissance d'images de produire de meilleures prédictions lorsque certaines informations sur une photo sont déjà connues à l'avance. La méthode, appelée feedback-prop, comble un écart entre la manière dont les systèmes de vision par ordinateur sont habituellement testés — en utilisant uniquement l'entrée visuelle — et la manière dont ils sont souvent utilisés en pratique, où du texte environnant, des données GPS, des étiquettes d'utilisateurs ou d'autres indices contextuels sont fréquemment disponibles. Plutôt que de réentraîner un réseau pour intégrer ces informations supplémentaires, les chercheurs ont constaté qu'ils pouvaient au contraire réinjecter les étiquettes connues à travers un réseau déjà entraîné pendant l'étape d'inférence elle-même, en ajustant les activations internes du réseau jusqu'à ce que les prédictions pour les étiquettes inconnues restantes s'améliorent. Ils ont testé deux variantes de l'approche — l'une qui met à jour les couches de manière séquentielle et l'autre qui injecte de petites variables correctrices à plusieurs couches simultanément — sur plusieurs tâches, dont l'identification d'objets dans des images lorsque certaines étiquettes sont déjà connues, la prédiction de catégories de scènes fines lorsque des catégories grossières sont fournies, et la génération de légendes d'images lorsque des annotations d'objets sont disponibles. Pour l'ensemble des tâches et de multiples architectures de réseaux standards, dont VGG-16 et ResNet, l'ajout d'informations partielles a systématiquement amélioré la précision, avec des gains relatifs allant d'environ 10 à 13 pour cent selon la tâche. Notamment, la technique ne nécessite aucune modification de l'entraînement du modèle original et fonctionne avec un mélange arbitraire d'étiquettes connues et inconnues, ce qui la rend largement applicable aux scénarios de déploiement réels où les images arrivent rarement sans aucun contexte associé.
résumé
Nous proposons une procédure d'inférence pour les réseaux de neurones convolutifs profonds (CNN) lorsque des éléments d'information partiels sont disponibles. Notre méthode consiste en une approche générale de propagation fondée sur la rétroaction (feedback-prop) qui améliore la précision de prédiction pour un ensemble arbitraire d'étiquettes cibles inconnues lorsque les valeurs d'un ensemble arbitraire et disjoint d'étiquettes cibles sont connues. Nous montrons que des modèles existants entraînés dans un cadre multi-étiquettes ou multi-tâches peuvent aisément tirer parti de feedback-prop sans aucun réentraînement ni affinage. Notre procédure d'inférence feedback-prop est générale, simple, fiable et fonctionne sur différentes tâches difficiles de reconnaissance visuelle. Nous présentons deux variantes de feedback-prop fondées sur des mises à jour itératives couche par couche et résiduelles. Nous menons des expériences avec plusieurs modèles multi-tâches et montrons que feedback-prop est efficace pour chacun d'eux. Nos résultats révèlent une propriété dynamique des CNN profonds intéressante et jusqu'ici non rapportée. Nous présentons également une approche technique associée qui exploite cette propriété pour l'inférence sous information partielle dans des tâches générales de reconnaissance visuelle.
détails
citation
@inproceedings{wang2018feedback,
title = {Feedback-prop: Convolutional Neural Network Inference under Partial Evidence},
author = {Wang, Tianlu and Yamaguchi, Kota and Ordonez, Vicente},
year = {2018},
booktitle = {Conference on Computer Vision and Pattern Recognition. CVPR 2018},
url = {https://arxiv.org/abs/1710.08049},
}