General Multi-label Image Classification with Transformers
Sintesi del comunicato stampa
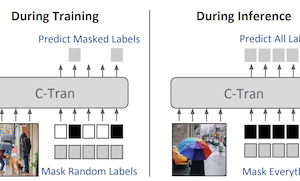
I ricercatori della University of Virginia hanno sviluppato un nuovo sistema di deep learning, chiamato Classification Transformer (C-Tran), che migliora la capacità di un computer di identificare più oggetti o concetti contemporaneamente all'interno di una singola immagine — un compito noto come classificazione di immagini multi-etichetta. A differenza della maggior parte degli approcci esistenti, che trattano ciascuna previsione di etichetta in gran parte in isolamento o si affidano a grafi di conoscenza predefiniti per cogliere le relazioni tra le etichette, C-Tran fornisce congiuntamente sia le caratteristiche dell'immagine sia le informazioni sulle etichette a un encoder Transformer, lo stesso tipo di architettura che ha guidato i recenti progressi nell'elaborazione del linguaggio naturale. L'innovazione chiave è una procedura di addestramento chiamata Label Mask Training, in cui il modello impara a prevedere etichette nascoste in modo casuale data una conoscenza parziale delle altre, in modo molto simile agli esercizi di completamento utilizzati per addestrare modelli linguistici come BERT. Questo approccio insegna al sistema a capire come le etichette si relazionano tra loro — per esempio, che una forchetta e un coltello tendono a comparire insieme — senza bisogno di regole costruite a mano. Oltre alla classificazione standard, C-Tran può anche accettare informazioni parziali sulle etichette in fase di inferenza, il che significa che un utente può comunicare al modello che certe etichette sono sicuramente presenti o assenti e ricevere previsioni più accurate per le rimanenti incognite. Il sistema ha ottenuto risultati allo stato dell'arte su dataset di riferimento come Microsoft COCO e Visual Genome, e ha inoltre superato i metodi concorrenti quando testato con etichette parzialmente note o supplementari su quattro dataset. Il significato pratico è che le immagini del mondo reale spesso si accompagnano a metadati incompleti o contestuali — come tag di posizione o didascalie — e C-Tran è il primo modello progettato per sfruttare in modo flessibile questo tipo di evidenza parziale all'interno di un unico framework unificato.
abstract
La classificazione di immagini multi-etichetta è il compito di prevedere un insieme di etichette corrispondenti a oggetti, attributi o altre entità presenti in un'immagine. In questo lavoro proponiamo il Classification Transformer (C-Tran), un framework generale per la classificazione di immagini multi-etichetta che sfrutta i Transformer per cogliere le complesse dipendenze tra le caratteristiche visive e le etichette. Il nostro approccio consiste in un encoder Transformer addestrato a prevedere un insieme di etichette obiettivo dato un insieme di etichette mascherate in input e caratteristiche visive provenienti da una rete neurale convoluzionale. Un ingrediente chiave del nostro metodo è un obiettivo di addestramento a maschera di etichette che utilizza uno schema di codifica ternario per rappresentare lo stato delle etichette come positivo, negativo o sconosciuto durante l'addestramento. Il nostro modello mostra prestazioni allo stato dell'arte su dataset impegnativi come COCO e Visual Genome. Inoltre, poiché il nostro modello rappresenta esplicitamente l'incertezza delle etichette durante l'addestramento, è più generale in quanto ci consente di produrre risultati migliori per immagini con annotazioni di etichette parziali o aggiuntive in fase di inferenza. Dimostriamo questa capacità aggiuntiva sui dataset di immagini COCO, Visual Genome, News500 e CUB.
dettagli
citazione
@inproceedings{lanchantin2021general,
title = {General Multi-label Image Classification with Transformers},
author = {Lanchantin, Jack and Wang, Tianlu and Ordonez, Vicente and Qi, Yanjun},
year = {2021},
booktitle = {Conference on Computer Vision and Pattern Recognition CVPR 2021},
url = {https://arxiv.org/abs/2011.14027},
}