Questa demo cerca di evidenziare aree di un'immagine condizionate da un testo di input arbitrario.
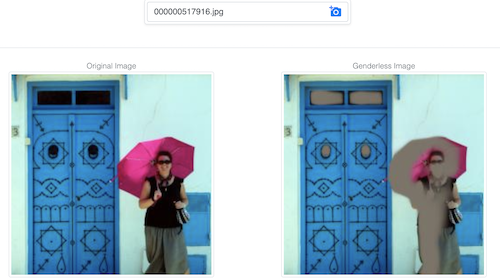
Questa demo cerca di rendere difficile per un modello prevedere il genere a partire da un'immagine, modificandola in modo che questo compito diventi più arduo pur conservando gran parte delle informazioni dell'immagine.
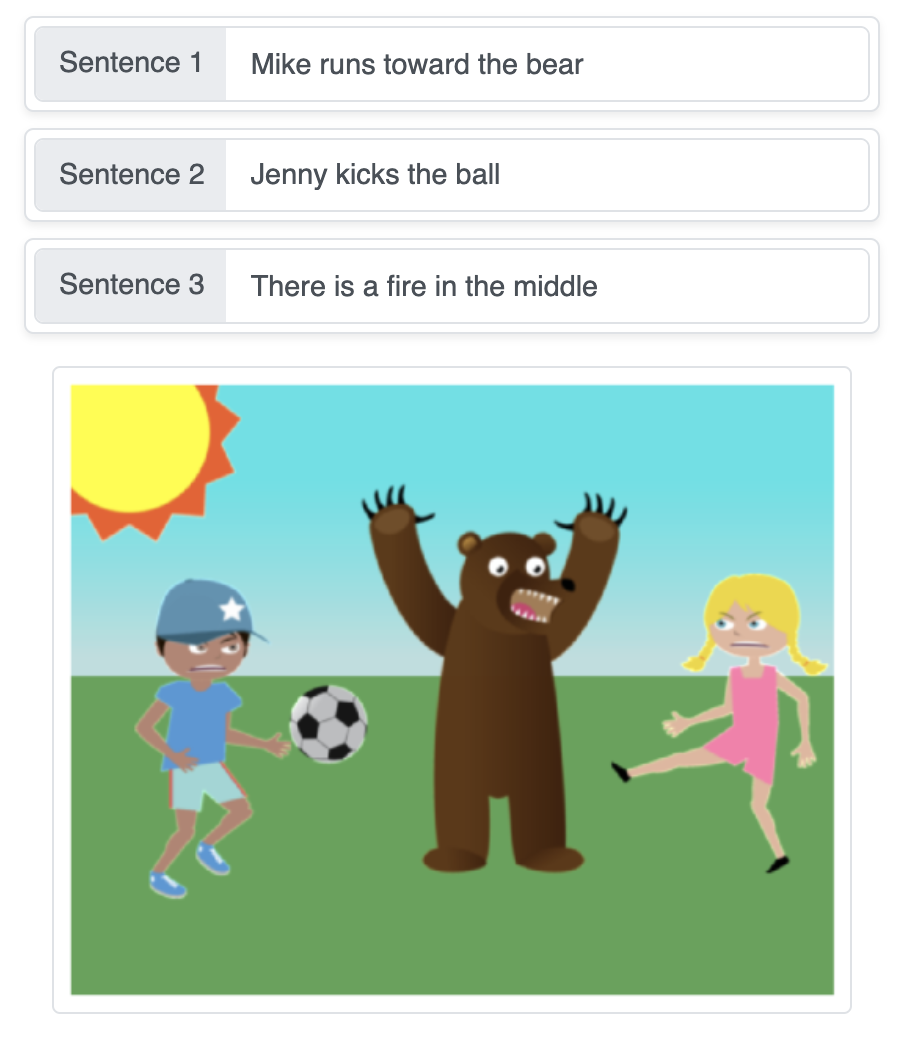
Questa demo trasforma descrizioni testuali in una scena generata automaticamente, assemblando gli oggetti in sequenza su uno sfondo semplice, passo dopo passo, utilizzando reti neurali di generazione di sequenze.
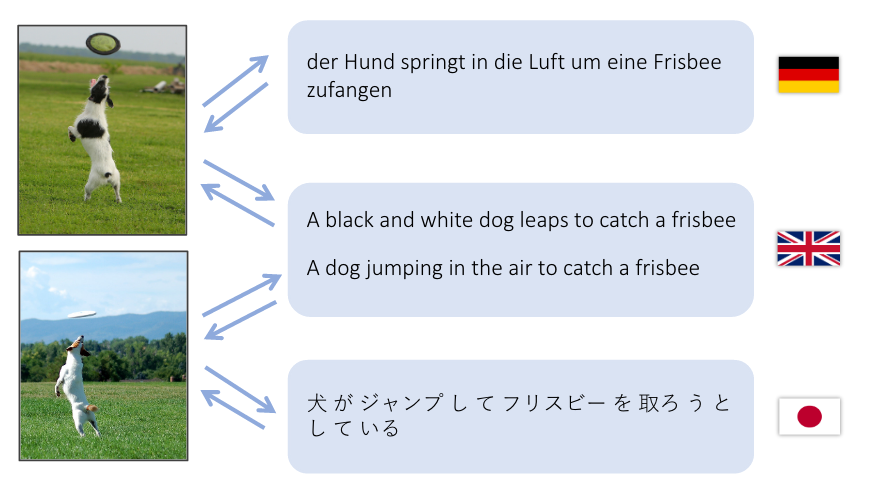
Questa demo cerca di tradurre una frase in inglese in uno spazio di caratteristiche visive e in una frase sia in tedesco (Deutsch) sia in giapponese (日本語).
Cerca immagini tramite testo nel dataset SBU Captions, che contiene 1 milione di immagini con didascalie provenienti da Flickr ed è stato utilizzato in numerosi progetti.
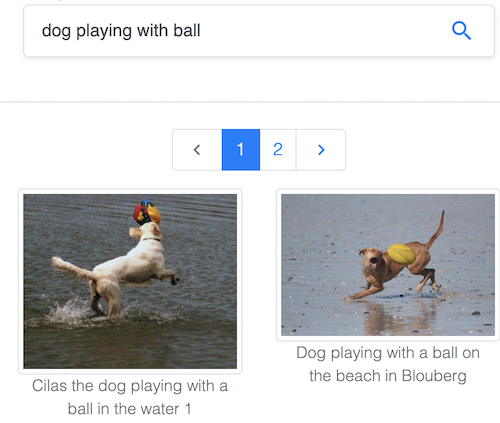
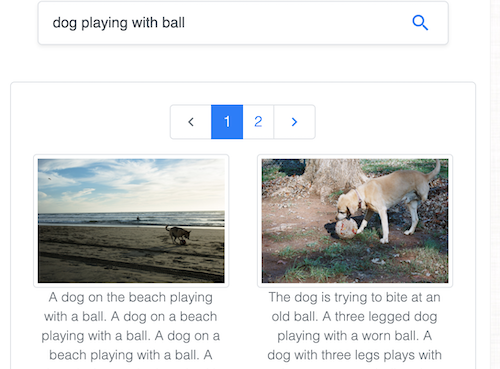
Cerca immagini tramite testo nel celebre dataset Common Objects in Context (COCO), gestito dalla Common Visual Data Foundation.