LoCoRe: Image Re-ranking with Long-Context Sequence Modeling
Sintesi del comunicato stampa
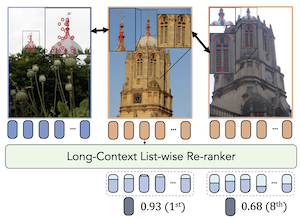
I ricercatori della Rice University e della Czech Technical University in Prague hanno sviluppato un nuovo sistema di recupero di immagini chiamato LOCORE che ripensa il modo in cui i motori di ricerca restringono e ri-classificano le immagini candidate dopo una prima ricerca ampia. I sistemi di ri-classificazione tradizionali confrontano un'immagine query con ciascuna immagine candidata individualmente, una coppia alla volta, il che significa che perdono relazioni utili tra le stesse immagini candidate — ad esempio, il fatto che due immagini della galleria potrebbero condividere caratteristiche che, insieme, forniscono un'evidenza più forte di una corrispondenza. LOCORE elabora invece la query insieme a un'intera rosa ristretta di un massimo di 100 immagini candidate simultaneamente, utilizzando un modello transformer a contesto lungo chiamato Longformer, originariamente sviluppato per documenti di testo lunghi, per catturare tali dipendenze tra immagini a livello di descrittori visivi locali a grana fine. Per gestire le situazioni in cui la rosa ristretta supera ciò che il modello può contenere in memoria in una sola volta, il team ha progettato una strategia a finestra scorrevole che attraversa la lista dei candidati in blocchi sovrapposti. Nei test su cinque dataset di benchmark che coprono monumenti, prodotti, articoli di moda e specie di uccelli, LOCORE ha costantemente superato i metodi di ri-classificazione esistenti, inclusi gli approcci a coppie che utilizzano descrittori locali e gli approcci list-wise che utilizzano descrittori globali, operando con latenza comparabile o inferiore e utilizzando significativamente meno memoria. Il lavoro è importante perché una migliore ri-classificazione migliora direttamente l'accuratezza dei sistemi di ricerca di immagini, e l'approccio dimostra che idee dell'elaborazione del linguaggio naturale — in particolare la modellazione a contesto lungo e la classificazione a livello di token — possono essere trasferite efficacemente ai compiti di recupero visivo.
abstract
Presentiamo LOCORE, Long-Context Re-ranker, un modello che prende in input descrittori locali corrispondenti a un'immagine query e a una lista di immagini della galleria e produce in output punteggi di similarità tra la query e ciascuna immagine della galleria. Questo modello è utilizzato per il recupero di immagini, dove tipicamente un primo ranking viene eseguito con una misura di similarità efficiente, e poi una rosa ristretta delle immagini meglio classificate viene ri-classificata sulla base di una misura di similarità a grana più fine. Rispetto ai metodi esistenti che eseguono la stima di similarità a coppie con descrittori locali o la ri-classificazione list-wise con descrittori globali, LOCORE è il primo metodo a eseguire la ri-classificazione list-wise con descrittori locali. Per ottenere ciò, sfruttiamo efficienti modelli di sequenze a contesto lungo per catturare efficacemente le dipendenze tra la query e le immagini della galleria a livello di descrittore locale. Durante il test, elaboriamo lunghe rose ristrette con una strategia a finestra scorrevole, su misura per superare i limiti di dimensione del contesto dei modelli di sequenze. Il nostro approccio raggiunge prestazioni superiori rispetto agli altri re-ranker su benchmark consolidati di recupero di immagini relativi a monumenti (ROxf e RPar), prodotti (SOP), articoli di moda (In-Shop) e specie di uccelli (CUB-200), mantenendo al contempo una latenza comparabile a quella dei re-ranker a coppie basati su descrittori locali.
dettagli
citazione
@inproceedings{xiao2025locore,
title = {LoCoRe: Image Re-ranking with Long-Context Sequence Modeling},
author = {Xiao, Zilin and Suma, Pavel and Sachdeva, Ayush and Wang, Hao-Jen and Kordopatis-Zilos, Giorgos and Tolias, Giorgos and Ordonez, Vicente},
year = {2025},
booktitle = {Conf. on Computer Vision and Pattern Recognition. CVPR 2025},
url = {https://arxiv.org/abs/2503.21772},
}
domande, principali contributi e limiti di questo articolo generati automaticamente
Domande a cui questo articolo aiuta a rispondere
- Cos'è LOCORE e quale problema affronta? LOCORE è un modello di ri-classificazione di immagini a contesto lungo che elabora congiuntamente un'immagine query e una rosa ristretta di immagini della galleria utilizzando descrittori locali, migliorando il ranking di seconda fase utilizzato nei sistemi di recupero di immagini.
- In che cosa LOCORE differisce dai re-ranker a coppie? I metodi a coppie confrontano la query con ciascuna immagine della galleria in modo indipendente, mentre LOCORE modella l'intera rosa ristretta insieme, così da poter sfruttare le relazioni tra le immagini della galleria oltre alle corrispondenze query-galleria.
- Perché LOCORE utilizza un modello di sequenze a contesto lungo? Ri-classificare fino a 100 immagini della galleria con descrittori locali crea una lunga sequenza di token, e l'attenzione in stile Longformer consente al modello di catturare dipendenze utili con memoria e latenza gestibili.
- Come gestisce LOCORE le rose ristrette più lunghe della sua finestra di contesto? Utilizza una strategia a finestra scorrevole sovrapposta che riutilizza il re-ranker list-wise su parti della rosa ristretta, consentendo al metodo di migliorare i ranking oltre la dimensione massima della lista vista in un singolo passaggio in avanti.
- Quali benchmark di recupero migliora LOCORE? L'articolo riporta risultati di ri-classificazione di prim'ordine o allo stato dell'arte su benchmark di recupero relativi a monumenti, prodotti, moda e specie di uccelli, inclusi ROxf/RPar, SOP, In-Shop e CUB-200.
Principali contributi
- L'articolo introduce il primo framework di ri-classificazione di immagini list-wise che opera a livello di descrittore locale anziché affidarsi alla corrispondenza locale a coppie o ai descrittori globali list-wise.
- LOCORE riformula la ri-classificazione di immagini come un problema di classificazione a livello di token a contesto lungo, trasferendo idee dall'estrazione di span e dal sequence tagging dell'NLP al recupero visivo.
- Il modello utilizza l'attenzione globale sulla query, token separatori e l'addestramento con galleria mescolata per evitare scorciatoie posizionali e apprendere interazioni significative tra descrittori di immagini diverse.
- Su ROxf/RPar e le loro varianti con 1M di distrattori, LOCORE migliora rispetto ai precedenti re-ranker basati su descrittori locali come la verifica geometrica, RRT, CVNet e AMES a parità di impostazioni dei descrittori.
- Il metodo migliora anche i benchmark di recupero basati su metric learning, inclusi CUB-200, SOP e In-Shop, mostrando che la ri-classificazione list-wise con descrittori locali è utile oltre il recupero di monumenti.
Limiti e avvertenze
- LOCORE è un re-ranker di seconda fase anziché un sostituto del recupero efficiente di prima fase, il che è appropriato per pipeline di ricerca su larga scala in cui un descrittore globale compatto restringe prima la lista dei candidati.
- Il metodo dipende da descrittori locali di alta qualità provenienti da sistemi come DELG o DINOv2, ma ciò lo rende complementare ai progressi nell'estrazione di caratteristiche locali anziché legato a un singolo backbone.
- L'elaborazione a contesto lungo ha una finestra di contesto finita, quindi rose ristrette molto lunghe richiedono l'inferenza a finestra scorrevole; l'articolo mostra che questa strategia funziona bene e può estendere i benefici oltre la dimensione della lista di addestramento.
- L'addestramento richiede attenzione per evitare scorciatoie posizionali derivanti dal ranking globale iniziale, ma l'addestramento con galleria mescolata è una correzione semplice ed efficace dimostrata negli studi di ablazione.
- La valutazione si concentra su benchmark consolidati di recupero a livello di istanza, lasciando contesti di ricerca di produzione più ampi e collezioni di immagini specifiche di dominio come naturali studi di deployment successivi.
Come interpretare questo risultato
Questo articolo si legge al meglio come un solido contributo alla ri-classificazione nel recupero di immagini: LOCORE mostra che la modellazione list-wise a contesto lungo può rendere i descrittori locali più potenti, migliorando l'accuratezza su diversi benchmark mantenendo al contempo latenza e memoria pratiche per il recupero di seconda fase.