Chair Segments: A Compact Benchmark for the Study of Object Segmentation
Resumo do comunicado de imprensa
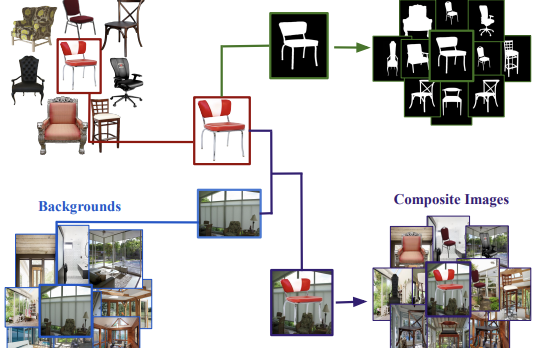
Pesquisadores da University of Virginia e instituições colaboradoras lançaram um novo conjunto de dados chamado Chair Segments, projetado para oferecer aos cientistas de visão computacional uma maneira mais rápida e barata de testar algoritmos de segmentação de imagens. O problema central que identificaram é que os conjuntos de dados de segmentação existentes — como COCO ou PASCAL VOC — são grandes, caros de anotar e forçam os modelos a lidar simultaneamente com reconhecimento de objetos, localização e mascaramento em nível de pixel, dificultando isolar e iterar rapidamente sobre ideias específicas de segmentação. Para contornar isso, a equipe construiu um conjunto de dados semissintético de cerca de 900 imagens de cadeiras com fundos transparentes, compostas sobre 10.000 imagens diversas de cenas internas e externas, produzindo 50.000 composições de treinamento com máscaras de referência perfeitas em nível de pixel que não exigiram nenhuma anotação manual. Os pesquisadores escolheram cadeiras deliberadamente: a categoria é notoriamente difícil de segmentar devido a partes finas, vazadas e que se autoocluem, e está entre as mais difíceis nos benchmarks existentes. Seus experimentos mostraram que um modelo U-Net pode ser treinado até a convergência total no conjunto de dados em cerca de 30 minutos em uma única GPU na resolução de 64×64 — aproximadamente o nível de complexidade do CIFAR-10 para classificação — enquanto ainda distingue de forma significativa entre arquiteturas mais fortes e mais fracas. É importante notar que modelos pré-treinados no Chair Segments e depois ajustados no conjunto de dados não relacionado Object Discovery (que abrange carros, cavalos e aviões) superaram todos os métodos anteriormente publicados nesse benchmark, sugerindo que os dados semissintéticos capturam características do mundo real genuinamente úteis. A equipe também confirmou, pela primeira vez em segmentação, um padrão observado anteriormente na classificação de imagens: modelos ajustados a partir dos mesmos pesos pré-treinados se agrupam no panorama de otimização e transitam suavemente entre si, enquanto modelos treinados a partir de inicialização aleatória não fazem isso — uma descoberta com implicações práticas para como os modelos de segmentação podem ser inicializados e combinados em conjuntos.
resumo
Ao longo dos anos, conjuntos de dados e benchmarks tiveram uma influência desproporcional no projeto de novos algoritmos. Neste artigo, apresentamos o ChairSegments, um conjunto de dados semissintético novo e compacto para segmentação de objetos. Também apresentamos descobertas empíricas em aprendizado por transferência que espelham descobertas recentes na classificação de imagens. Em particular, mostramos que modelos ajustados a partir de um conjunto pré-treinado de pesos situam-se na mesma bacia do panorama de otimização. O ChairSegments consiste em um conjunto diversificado de imagens prototípicas de cadeiras com fundos transparentes compostas sobre uma variedade diversa de fundos. Pretendemos que o ChairSegments seja o equivalente ao conjunto de dados CIFAR-10, mas voltado para projetar e iterar rapidamente sobre novas arquiteturas de modelo para segmentação. No Chair Segments, um modelo U-Net pode ser treinado até a convergência total em apenas trinta minutos usando uma única GPU. Por fim, embora esse conjunto de dados seja semissintético, ele pode ser um substituto útil para dados reais, levando a uma acurácia de ponta no conjunto de dados Object Discovery quando usado como fonte de pré-treinamento.
detalhes
citação
@article{pintoalva2011chair,
title = {Chair Segments: A Compact Benchmark for the Study of Object Segmentation},
author = {Pinto-Alva, Leticia and Torres, Ian K. and Garcia, Rosangel and Yang, Ziyan and Ordonez, Vicente},
year = {2011},
journal = {arxiv:2011.14027 Nov 2020.},
url = {https://arxiv.org/abs/2012.01250},
}