Evolving Image Compositions for Feature Representation Learning
News Release Summary
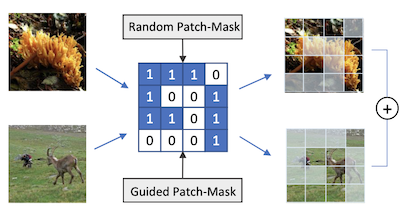
Researchers at the University of Virginia and Rice University have developed a data augmentation technique called PatchMix that helps image-recognition neural networks learn better by training on artificially constructed hybrid images. The core problem is that deep learning models for visual recognition tend to overfit their training data, and while existing methods like Mixup and CutMix already blend pairs of images together to combat this, they are limited in how flexibly they can combine those images. PatchMix addresses this by slicing two images into a grid of equal-sized patches and swapping patches between them according to a binary mask, then assigning the resulting composite image a blended label proportional to how many patches came from each source. The team also added a secondary loss function that trains the network to correctly identify what class each individual patch belongs to, not just the image as a whole, which forces the model to build more locally aware representations. Going further, the researchers used a genetic search algorithm to automatically discover which pairs of image categories are most useful to mix together, and what grid patterns produce the most challenging — and therefore most informative — training examples, all without needing to retrain the model from scratch for each candidate configuration. Tested against standard benchmarks, a ResNet-50 model trained with PatchMix outperformed baseline models on CIFAR-10, CIFAR-100, Tiny ImageNet, and ImageNet, and showed stronger transfer learning performance across tasks including object detection, scene recognition, and image captioning, suggesting the method produces more general-purpose visual features than competing approaches.
abstract
Convolutional neural networks for visual recognition require large amounts of training samples and usually benefit from data augmentation. This paper proposes PatchMix, a data augmentation method that creates new samples by composing patches from pairs of images in a grid-like pattern. These new samples are assigned label scores that are proportional to the number of patches borrowed from each image. We then add a set of additional losses at the patch-level to regularize and to encourage good representations at both the patch and image levels. A ResNet-50 model trained on ImageNet using PatchMix exhibits superior transfer learning capabilities across a wide array of benchmarks. Although PatchMix can rely on random pairings and random grid-like patterns for mixing, we explore evolutionary search as a guiding strategy to jointly discover optimal grid-like patterns and image pairings. For this purpose, we conceive a fitness function that bypasses the need to re-train a model to evaluate each possible choice. In this way, PatchMix outperforms a base model on CIFAR-10 (+1.91), CIFAR-100 (+5.31), Tiny Imagenet (+3.52), and ImageNet (+1.16).
details
citation
@inproceedings{cascantebonilla2021evolving,
title = {Evolving Image Compositions for Feature Representation Learning},
author = {Cascante-Bonilla, Paola and Sekhon, Arshdeep and Qi, Yanjun and Ordonez, Vicente},
year = {2021},
booktitle = {British Machine Vision Conference. BMVC 2021},
url = {https://arxiv.org/abs/2106.09011},
}