This demo attemps to highlight areas of an image conditioned on an arbitrary input text.
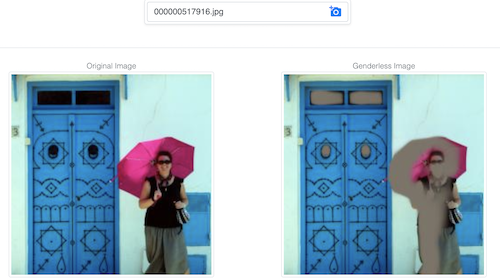
This demo attemps to make it difficult for a model to predict gender from an image by modifying it so that this task becomes harder while retaining most image information.
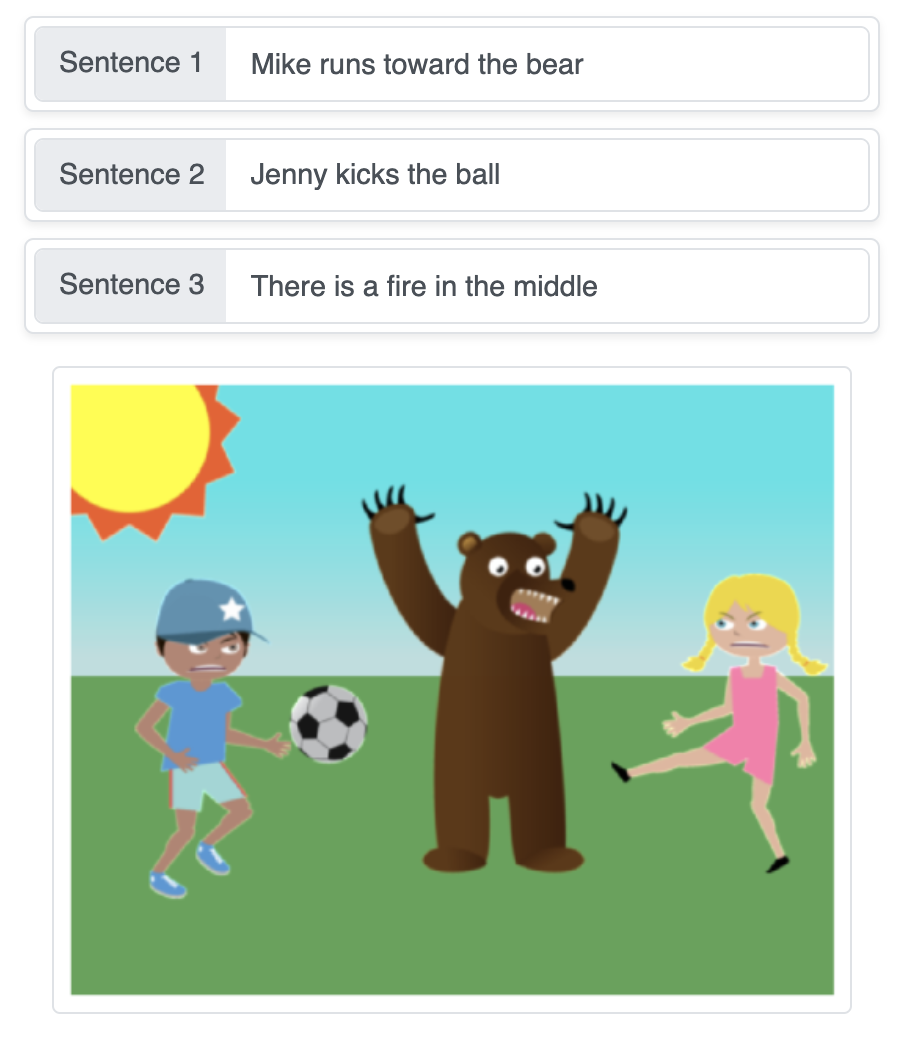
This demo turns textual descriptions into a scene generated automatically by stitching objects sequentially on a plain background step-by-step using sequence generation neural networks.
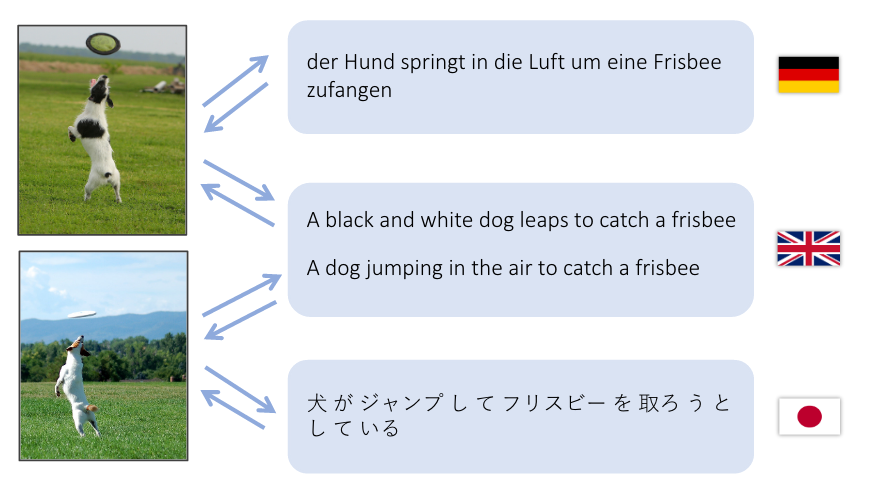
This demo attemps to translate a sentence in English into visual feature space and into a sentence in both German (Deutsch) and Japanese (日本語).
Search images by text in the SBU Captions Dataset which has 1 million images with captions from Flickr and has been used in numerous projects
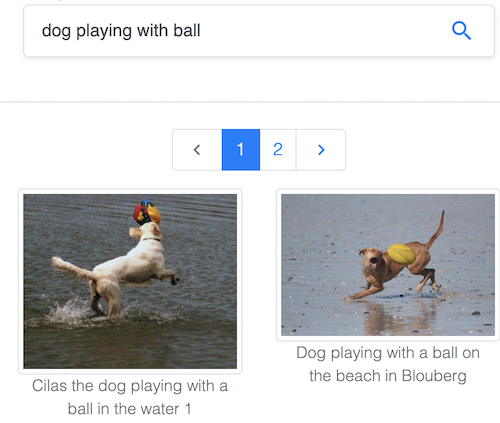
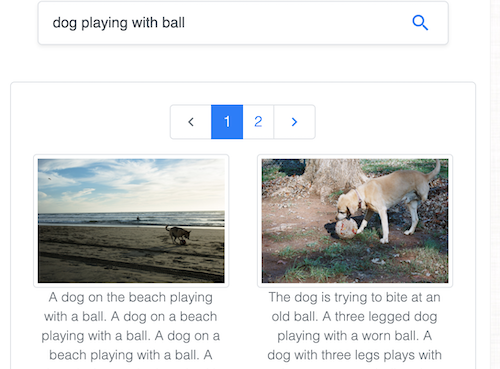
Search images by text in the popular Common Objects in Context (COCO) dataset maintained by the Common Visual Data Foundation.