GViT: Representing Images as Gaussians for Visual Recognition
News Release Summary
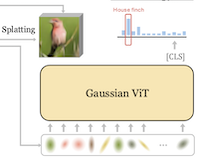
Researchers at Rice University and UC Irvine have built a new image classification system that ditches the conventional approach of feeding a neural network a grid of pixels or rectangular patches, replacing that input with a compact set of mathematical blobs called 2D Gaussians. The system, called GViT, works by training a small encoder network to describe each image using a few hundred Gaussians, where each blob carries information about its position, size, orientation, color, and opacity. The clever part of the training setup is that the classification model and the Gaussian encoder are trained together in a feedback loop: gradients from the classifier — essentially signals about which parts of an image matter for identifying its content — are fed back to steer the Gaussians toward the regions that are actually useful for recognition, rather than letting them spread uniformly across uninformative background. Using this approach on the standard ImageNet-1k benchmark, the best version of GViT reached 76.9% top-1 accuracy with a ViT-Base architecture, compared to roughly 78.7% for a conventional patch-based ViT of similar size — a gap of less than two percentage points while using a fundamentally different and far more compact input representation. The work matters not because it immediately outperforms existing systems, but because it demonstrates that intermediate, human-interpretable geometric primitives can support competitive visual recognition, and as a byproduct the learned Gaussians tend to cluster around the parts of a scene the model finds most discriminative, offering a lightweight form of explainability that pixel-grid models do not naturally provide.
abstract
We introduce GVIT, a classification framework that abandons conventional pixel or patch grid input representations in favor of a compact set of learnable 2D Gaussians. Each image is encoded as a few hundred Gaussians whose positions, scales, orientations, colors, and opacities are optimized jointly with a ViT classifier trained on top of these representations. We reuse the classifier gradients as constructive guidance, steering the Gaussians toward class-salient regions while a differentiable renderer optimizes an image reconstruction loss. We demonstrate that by 2D Gaussian input representations coupled with our GVIT guidance, using a relatively standard ViT architecture, closely matches the performance of a traditional patch-based ViT, reaching a 76.9% top-1 accuracy on Imagenet-1k using a ViT-B architecture.
citation
@article{hernandezgvit,
title = {GViT: Representing Images as Gaussians for Visual Recognition},
author = {Hernandez, Jefferson and He, Ruozhen and Balakrishnan, Guha and Berg, Alexander C. and Ordonez, Vicente},
journal = {arXiv preprint arXiv:2506.23532},
url = {https://arxiv.org/abs/2506.23532},
}
automatically generated questions, main contributions and limitations of this paper
Questions this paper helps answer
- What is GViT and what problem does it address? GViT is a visual recognition framework that replaces fixed pixel or patch-grid inputs with a compact set of learnable 2D Gaussian primitives, testing whether mid-level geometric representations can support competitive image classification.
- How are the Gaussians learned? A denoising Gaussian encoder predicts Gaussian centers, scales, orientations, colors, and opacities, while a differentiable renderer optimizes image reconstruction and a ViT classifier supplies constructive gradients that steer Gaussians toward class-salient regions.
- How well does GViT perform on ImageNet-1k? The guided GViT-B model reaches 76.9 percent top-1 accuracy on ImageNet-1k, close to the 78.7 percent reported for a similarly sized patch-based ViT-B/16 while using a substantially different Gaussian input representation.
- Why is classifier-gradient guidance important? The paper reports that guidance improves GViT-B from 73.6 percent to 76.9 percent on ImageNet-1k and similarly improves smaller models, showing that task-aware Gaussian placement is central to making the representation useful for recognition.
- Does GViT provide interpretability benefits? Yes, the learned Gaussian covariances and class-discriminative attention maps tend to concentrate on class-relevant image regions, giving the representation a geometric visual explanation that standard patch tokens do not naturally expose.
Main contributions
- The paper introduces a ViT-compatible image representation based on sets of 2D Gaussian primitives rather than pixels, patches, raw bytes, or compressed frequency coefficients.
- GViT proposes a cooperative training scheme in which reconstruction losses preserve image fidelity while classifier gradients actively relocate Gaussians toward discriminative visual evidence.
- The ImageNet-1k experiments show that Gaussian inputs can reach 76.9 percent top-1 accuracy with a ViT-B backbone, outperforming several non-patch input alternatives listed in the paper and coming within 1.8 points of a conventional patch-based ViT-B/16.
- Ablations on Mini-ImageNet-100 show that denoising and classifier-gradient guidance meaningfully improve Gaussian placement, with the full guided version outperforming offline Gaussian fitting, learned queries, and unguided denoising.
- The analysis shows that Gaussian scale and attention signals align with class-discriminative regions, supporting the claim that GViT offers a compact recognition representation with a natural interpretability component.
Limitations and cautions
- Patch-based ViTs remain the most pragmatic choice for many large-scale deployments today, but GViT's small accuracy gap on ImageNet-1k makes a strong case that Gaussian primitives are already a viable and surprisingly competitive alternative representation.
- The number of Gaussians is fixed before training, so future versions could benefit from dynamic spawning, pruning, or reallocation; the monotonic gains observed as the Gaussian budget increases provide useful guidance for that next design step.
- Differentiable rendering adds memory and compute overhead, especially at high resolutions or with more than 512 Gaussians on ImageNet-scale training; this is an engineering bottleneck around an otherwise promising representation rather than a weakness of the core idea.
- The experiments focus on image classification and transfer classification benchmarks rather than dense prediction tasks such as detection or segmentation; the class-salient Gaussian layouts suggest those tasks are natural places to explore the representation next.
- The current approach compresses away some fine-grained pixel detail by design, which helps make the representation compact and interpretable while leaving room for future work to tune the balance between reconstruction fidelity and semantic discrimination.
How to read this result
This paper is best read as a strong evidence-backed argument that visual recognition does not have to be tied to pixel or patch grids: GViT keeps ImageNet performance close to standard ViTs while introducing an interpretable Gaussian representation that opens a promising direction for future vision backbones.