VisualNews : Benchmark and Challenges in Entity-aware Image Captioning
News Release Summary
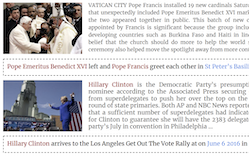
Researchers at the University of Maryland, University of Virginia, and Rice University have released Visual News, a dataset of more than one million news images paired with article text, captions, and metadata drawn from four outlets — The Guardian, BBC, USA Today, and The Washington Post — making it the largest collection of its kind to date. The work addresses a genuine gap in image captioning research: existing datasets like Microsoft COCO train models to produce generic descriptions such as "a bunch of people holding red umbrellas," which fail to capture the who, where, and what that make a news photo meaningful. To put the dataset to use, the team also built Visual News Captioner, a Transformer-based model that pulls from both the image and the accompanying article text to generate captions containing specific named entities — people, places, and organizations — rather than vague placeholders. The model introduces several technical additions, including an "Attention on Attention" mechanism, a Visual Selective Layer that links image and text features during encoding, and a Tag-Cleaning step to handle rare words that fall outside the model's vocabulary. Tested against competing approaches on three datasets, Visual News Captioner matched or beat the state of the art on standard captioning metrics while using roughly half the number of parameters of its closest rival. The researchers also found that models trained on data from one news agency performed noticeably worse when tested on another agency's content, underscoring just how much writing style and editorial focus vary across newsrooms — and how much harder the problem becomes in a truly diverse setting.
abstract
We propose Visual News Captioner, an entity-aware model for the task of news image captioning. We also introduce Visual News, a large-scale benchmark consisting of more than one million news images along with associated news articles, image captions, author information, and other metadata. Unlike the standard image captioning task, news images depict situations where people, locations, and events are of paramount importance. Our proposed method can effectively combine visual and textual features to generate captions with richer information such as events and entities. More specifically, built upon the Transformer architecture, our model is further equipped with novel multi-modal feature fusion techniques and attention mechanisms, which are designed to generate named entities more accurately. Our method utilizes much fewer parameters while achieving slightly better prediction results than competing methods. Our larger and more diverse Visual News dataset further highlights the remaining challenges in captioning news images.
details
citation
@inproceedings{liu2021visualnews,
title = {VisualNews : Benchmark and Challenges in Entity-aware Image Captioning},
author = {Liu, Fuxiao and Wang, Yinghan and Wang, Tianlu and Ordonez, Vicente},
year = {2021},
booktitle = {Empirical Methods in Natural Language Processing. EMNLP 2021},
url = {https://arxiv.org/abs/2010.03743},
}