Grounding Language Models for Visual Entity Recognition
News Release Summary
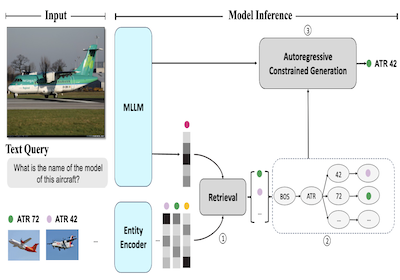
Researchers at Rice University and Microsoft have developed a system called AutoVER that dramatically improves a computer's ability to identify specific real-world entities in images — think distinguishing one particular airplane model from another nearly identical one — by anchoring an AI language model's guesses to a concrete knowledge base rather than letting it generate whatever answer seems plausible. The core problem is that existing multimodal AI systems, which process both images and text, tend to hallucinate or produce answers at the wrong level of specificity when asked fine-grained recognition questions, such as identifying whether a pictured aircraft is an ATR 42 versus a British Aerospace 146. AutoVER tackles this by combining two techniques: it trains the model to retrieve visually and semantically similar candidate entities from a database of over six million Wikipedia entries using a contrastive learning approach, and then during answer generation it restricts the model's output to only those retrieved candidates by building a prefix tree that blocks any token sequences that would lead to invalid answers. The system was tested on the Oven-Wiki benchmark, a large-scale dataset specifically designed for this kind of visual entity recognition challenge, where it pushed accuracy on entities the model had seen in training from around 32.7 percent to 61.5 percent, while also outperforming much larger models like Google's PaLI-17B on examples involving unseen entities and questions requiring visual reasoning. The work matters because reliable entity recognition from images has practical applications in areas ranging from search engines to accessibility tools, and the approach demonstrates that tightly coupling retrieval with constrained generation is a more dependable path than simply scaling up a model and hoping it gets specific enough answers right.
abstract
We introduce AutoVER, an Autoregressive model for Visual Entity Recognition. Our model extends an autoregressive Multi-modal Large Language Model by employing retrieval augmented constrained generation. It mitigates low performance on out-of-domain entities while excelling in queries that require visually-situated reasoning. Our method learns to distinguish similar entities within a vast label space by contrastively training on hard negative pairs in parallel with a sequence-to-sequence objective without an external retriever. During inference, a list of retrieved candidate answers explicitly guides language generation by removing invalid decoding paths. The proposed method achieves significant improvements across different dataset splits in the recently proposed Oven-Wiki benchmark. Accuracy on the Entity seen split rises from 32.7% to 61.5%. It also demonstrates superior performance on the unseen and query splits by a substantial double-digit margin.
details
citation
@inproceedings{xiao2024grounding,
title = {Grounding Language Models for Visual Entity Recognition},
author = {Xiao, Zilin and Gong, Ming and Cascante-Bonilla, Paola and Zhang, Xingyao and Wu, Jie and Ordonez, Vicente},
year = {2024},
booktitle = {European Conference on Computer Vision ECCV 2024},
url = {https://arxiv.org/abs/2402.18695},
}
automatically generated questions, main contributions and limitations of this paper
Questions this paper helps answer
- What is AutoVER? AutoVER is an autoregressive multimodal language model for visual entity recognition, where answers must be grounded to specific entities in a large knowledge base.
- What problem does the paper address? It tackles fine-grained image-based entity recognition, where models must distinguish visually similar entities and avoid hallucinating answers outside the valid entity space.
- How does retrieval-augmented constrained generation work here? AutoVER retrieves likely entities, builds a dynamic prefix tree from those candidates, and constrains decoding so generation follows only valid entity-name token paths.
- Why use contrastive learning and hard negatives? The model learns query-to-entity retrieval with visually and knowledge-similar hard negatives, helping it separate entities that share appearance or category structure.
- Where is AutoVER evaluated? The paper evaluates on Oven-Wiki and also tests zero-shot transfer on an entity-grounded subset of A-OKVQA.
Main contributions
- The paper introduces AutoVER, a retrieval-augmented autoregressive framework for grounding multimodal language model outputs to Wikipedia-scale visual entities.
- It integrates query-to-entity contrastive training directly into the multimodal language model, avoiding dependence on a separate external retriever.
- The constrained decoding mechanism ensures generated answers are grounded in retrieved candidate entities, directly reducing invalid or ungrounded generations.
- Hard-negative mining from visual similarity and knowledge-base hierarchy improves fine-grained discrimination among visually similar entities.
- AutoVER substantially improves Oven-Wiki performance, including increasing Entity seen accuracy from 32.7% to 61.5% in the reported comparison and outperforming larger PaLI baselines on unseen and query splits.
Limitations and cautions
- AutoVER depends on the coverage and quality of the entity knowledge base, which is appropriate for visual entity recognition and makes the grounding target explicit.
- The method retrieves a candidate set before constrained decoding, so very rare or visually ambiguous entities remain challenging when retrieval misses them; the paper addresses this directly with entity-side visual features and hard-negative training.
- Training at Wikipedia scale requires substantial data and compute, but the result is a practical framework for turning large knowledge bases into usable visual recognition targets.
- The paper still shows a gap to human plus search performance on the human evaluation set, which is a useful benchmark for future progress rather than a weakness of the core approach.
- AutoVER is specialized for entity-grounded answers, complementing broader open-ended VQA systems when the desired output should be a precise named entity.
How to read this result
This paper is best read as a strong contribution to grounded multimodal recognition: AutoVER shows that retrieval, contrastive entity learning, and constrained generation can make language-model answers much more precise and trustworthy for Wikipedia-scale visual entity recognition.