ProxyThinker: Test-Time Guidance through Small Visual Reasoners
News Release Summary
Researchers at Rice University, the University of Illinois Urbana-Champaign, and the University of Virginia have developed a method called ProxyThinker that lets large vision-language models reason more carefully at test time — without any additional training. The problem they set out to solve is a practical one: teaching large AI models to "slow down" and work through complex visual problems step by step typically requires expensive reinforcement fine-tuning, a process that demands enormous compute resources and has rarely been applied to models larger than seven billion parameters. ProxyThinker sidesteps that cost entirely by running two small companion models alongside the large model during inference — one that has already been fine-tuned to reason carefully, and one that has not — and using the difference between their output distributions to nudge the large model's token-by-token generation toward more deliberate, self-checking reasoning. In practice, this means the large model starts exhibiting behaviors like backtracking, self-verification, and multi-step correction that it would otherwise rarely produce. Testing the approach on standard visual math and multi-disciplinary benchmarks, the team found that a 32-billion-parameter base model steered by a weak 7-billion-parameter reasoning expert could match or slightly exceed the performance of a dedicated 32-billion-parameter model that had been fully fine-tuned with reinforcement learning. The team also engineered a parallelized implementation on top of the vLLM inference framework that runs about 38 times faster than earlier decoding-time steering methods, bringing the wall-clock inference time close to simply running a single large model. The work matters because it offers a computationally accessible path to stronger visual reasoning in large models at a time when the training costs of frontier-scale reinforcement fine-tuning remain out of reach for most research groups.
abstract
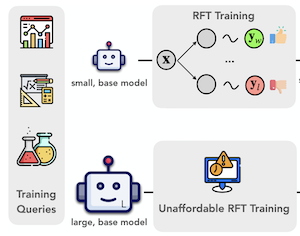
Recent advancements in reinforcement learning with verifiable rewards have pushed the boundaries of the visual reasoning capabilities in large vision-language models (LVLMs). However, training LVLMs with reinforcement fine-tuning (RFT) is computationally expensive, posing a significant challenge to scaling model size. In this work, we propose ProxyThinker, an inference-time technique that enables large models to inherit the visual reasoning capabilities from small, slow-thinking visual reasoners without any training. By subtracting the output distributions of base models from those of RFT reasoners, ProxyThinker modifies the decoding dynamics and successfully elicits the slow-thinking reasoning demonstrated by the emerged sophisticated behaviors such as self-verification and self-correction. ProxyThinker consistently boosts performance on challenging visual benchmarks on spatial, mathematical, and multi-disciplinary reasoning, enabling untuned base models to compete with the performance of their full-scale RFT counterparts. Furthermore, our implementation efficiently coordinates multiple language models with parallelism techniques and achieves up to 38 $\times$ faster inference compared to previous decoding-time methods, paving the way for the practical deployment of ProxyThinker. Code is available at https://github.com/MrZilinXiao/ProxyThinker.
citation
@inproceedings{xiao2026proxythinker,
title = {ProxyThinker: Test-Time Guidance through Small Visual Reasoners},
author = {Xiao, Zilin and Koo, Jaywon and Ouyang, Siru and Hernandez, Jefferson and Meng, Yu and Ordonez, Vicente},
year = {2026},
booktitle = {International Conference on Learning Representations. ICLR 2026},
url = {https://arxiv.org/abs/2505.24872},
}
automatically generated questions, main contributions and limitations of this paper
Questions this paper helps answer
- What is ProxyThinker and what problem does it address? ProxyThinker is a training-free inference-time method that transfers slow-thinking visual reasoning behavior from small reinforcement-fine-tuned visual reasoners to larger base vision-language models.
- How does ProxyThinker steer a large model? At each decoding step, it adds the logit difference between a small RFT reasoning expert and its small base amateur counterpart to the large base model's logits, encouraging the large model to generate tokens associated with self-checking and multi-step reasoning.
- Why is the method useful compared with full reinforcement fine-tuning? It avoids updating the large model's parameters, which makes it a practical alternative when full-scale reinforcement fine-tuning of 32B or 72B vision-language models is too expensive.
- How much does ProxyThinker improve visual reasoning benchmarks? On five mathematical and multi-disciplinary benchmarks, ProxyThinker improves Qwen2.5-VL-32B by up to 2.4 percent average relative improvement and Qwen2.5-VL-72B by up to 2.7 percent average relative improvement depending on the small reasoning expert.
- Does ProxyThinker change the reasoning style of the large model? Yes, the paper reports more backtracking, verification, and explicit thinking behaviors, showing that the method can elicit slow-thinking patterns rather than merely changing final answer probabilities.
Main contributions
- The paper introduces a simple decoding-time formulation for visual reasoning transfer that uses the token-level logit delta between a small RFT expert and a small amateur model as guidance for a larger base model.
- ProxyThinker shows that small visual reasoners can improve substantially larger models without training, including 32B and 72B vision-language models evaluated on MathVista, MathVerse, MathVision, MMMU-Pro, and R1-OneVisionBench.
- The method enables a Qwen2.5-VL-32B base model guided by a 7B expert to match or slightly exceed a full 32B RFT model on some benchmark settings, including the MathVision result highlighted in the paper.
- The behavioral analysis demonstrates that ProxyThinker can combine the large model's subgoal planning ability with the small expert's self-verification and backtracking tendencies.
- The vLLM-based implementation coordinates multiple models efficiently and reports a 38x speedup over earlier HuggingFace-style decoding-time steering implementations, making the approach much more practical.
Limitations and cautions
- ProxyThinker depends on having access to a useful small RFT visual reasoner and its matching base amateur model, so future work could broaden the recipe to more model families and open expert-amateur pairs.
- The method runs multiple models at inference time, which adds system complexity compared with a single-model baseline; the paper's optimized vLLM implementation substantially reduces this overhead and shows the approach can be practical.
- Performance gains vary across benchmarks and experts, with some settings showing smaller improvements than others; this variation usefully identifies expert selection and guidance strength as important knobs for future decoding-time reasoning systems.
- The experiments focus on established visual math and multi-disciplinary benchmarks, leaving interactive, long-horizon, and real-world deployment scenarios as natural next tests for the same guidance idea.
- ProxyThinker steers reasoning behavior at decoding time rather than changing the model's underlying weights, which is a feature for accessibility and cost, while future work could study how it complements training-time methods.
How to read this result
This paper is best read as a strong and practical contribution to efficient visual reasoning: ProxyThinker shows that small trained reasoners can unlock better slow-thinking behavior in much larger models at test time, offering a compelling alternative or complement to expensive full-scale reinforcement fine-tuning.