General Multi-label Image Classification with Transformers
Краткое изложение пресс-релиза
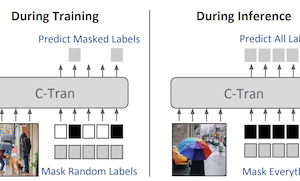
Исследователи из University of Virginia разработали новую систему Deep Learning под названием Classification Transformer (C-Tran), которая улучшает способность компьютера одновременно идентифицировать несколько объектов или концептов в пределах одного изображения — задачу, известную как многометочная классификация изображений. В отличие от большинства существующих подходов, которые рассматривают предсказание каждой метки в значительной степени изолированно или опираются на заранее определённые графы знаний для захвата взаимосвязей между метками, C-Tran подаёт как признаки изображения, так и информацию о метках совместно в энкодер-трансформер — тот самый тип архитектуры, который движет недавними достижениями в обработке естественного языка. Ключевое нововведение — это процедура обучения под названием Label Mask Training, в которой модель учится предсказывать случайно скрытые метки при частичном знании остальных, во многом подобно упражнениям на заполнение пропусков, используемым для обучения языковых моделей, таких как BERT. Этот подход учит систему понимать, как метки соотносятся друг с другом — например, что вилка и нож обычно появляются вместе — без необходимости в созданных вручную правилах. Помимо стандартной классификации, C-Tran может также принимать частичную информацию о метках во время инференса, что означает, что пользователь может сообщить модели, что определённые метки определённо присутствуют или отсутствуют, и получить более точные предсказания для оставшихся неизвестных. Система достигла результатов на современном уровне на бенчмарковых наборах данных, включая Microsoft COCO и Visual Genome, а также превзошла конкурирующие методы при тестировании с частично известными или дополнительными метками на четырёх наборах данных. Практическая значимость состоит в том, что изображения из реального мира часто сопровождаются неполными или контекстными метаданными — такими как теги местоположения или подписи — и C-Tran является первой моделью, разработанной для гибкого использования такого рода частичных свидетельств в рамках единого фреймворка.
аннотация
Многометочная классификация изображений — это задача предсказания набора меток, соответствующих объектам, атрибутам или другим сущностям, присутствующим на изображении. В этой работе мы предлагаем Classification Transformer (C-Tran) — общий фреймворк для многометочной классификации изображений, который использует трансформеры для эксплуатации сложных зависимостей между визуальными признаками и метками. Наш подход состоит из энкодера-трансформера, обученного предсказывать набор целевых меток при заданном входном наборе замаскированных меток и визуальных признаков из свёрточной нейронной сети. Ключевой компонент нашего метода — целевая функция обучения с маской меток, которая использует троичную схему кодирования для представления состояния меток как положительного, отрицательного или неизвестного во время обучения. Наша модель показывает производительность на современном уровне на сложных наборах данных, таких как COCO и Visual Genome. Более того, поскольку наша модель явно представляет неопределённость меток во время обучения, она более универсальна, позволяя нам получать улучшенные результаты для изображений с частичными или дополнительными аннотациями меток во время инференса. Мы демонстрируем эту дополнительную способность на наборах данных изображений COCO, Visual Genome, News500 и CUB.
подробности
цитирование
@inproceedings{lanchantin2021general,
title = {General Multi-label Image Classification with Transformers},
author = {Lanchantin, Jack and Wang, Tianlu and Ordonez, Vicente and Qi, Yanjun},
year = {2021},
booktitle = {Conference on Computer Vision and Pattern Recognition CVPR 2021},
url = {https://arxiv.org/abs/2011.14027},
}