General Multi-label Image Classification with Transformers
Tóm tắt thông cáo báo chí
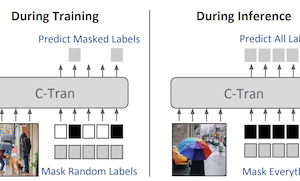
Các nhà nghiên cứu tại University of Virginia đã phát triển một hệ thống Deep Learning mới, gọi là Classification Transformer (C-Tran), cải thiện khả năng của máy tính trong việc nhận diện đồng thời nhiều đối tượng hoặc khái niệm trong một ảnh duy nhất — một nhiệm vụ được gọi là phân loại ảnh đa nhãn. Không giống như hầu hết các phương pháp hiện có, vốn xử lý mỗi dự đoán nhãn phần lớn một cách độc lập hoặc dựa vào các đồ thị tri thức được định nghĩa trước để nắm bắt các mối quan hệ giữa các nhãn, C-Tran đưa cả các đặc trưng ảnh lẫn thông tin nhãn vào chung một bộ mã hóa Transformer, cùng loại kiến trúc đã thúc đẩy những tiến bộ gần đây trong xử lý ngôn ngữ tự nhiên. Đổi mới then chốt là một quy trình huấn luyện gọi là Label Mask Training, trong đó mô hình học cách dự đoán các nhãn được giấu ngẫu nhiên khi cho biết một phần thông tin về những nhãn khác, giống như các bài tập điền vào chỗ trống được dùng để huấn luyện các mô hình ngôn ngữ như BERT. Cách tiếp cận này dạy hệ thống hiểu cách các nhãn liên hệ với nhau — chẳng hạn, rằng một cái nĩa và một con dao có xu hướng xuất hiện cùng nhau — mà không cần các quy tắc được chế tác thủ công. Ngoài việc phân loại tiêu chuẩn, C-Tran cũng có thể chấp nhận thông tin nhãn một phần tại thời điểm suy luận, nghĩa là một người dùng có thể cho mô hình biết rằng một số nhãn chắc chắn hiện diện hoặc vắng mặt và nhận được các dự đoán chính xác hơn cho những nhãn chưa biết còn lại. Hệ thống đã đạt được các kết quả tốt nhất hiện nay trên các bộ dữ liệu benchmark bao gồm Microsoft COCO và Visual Genome, và cũng vượt trội hơn các phương pháp cạnh tranh khi được kiểm tra với các nhãn đã biết một phần hoặc bổ sung trên bốn bộ dữ liệu. Ý nghĩa thực tiễn là các ảnh trong thế giới thực thường đi kèm với siêu dữ liệu không đầy đủ hoặc theo ngữ cảnh — chẳng hạn các thẻ vị trí hoặc chú thích — và C-Tran là mô hình đầu tiên được thiết kế để khai thác một cách linh hoạt loại bằng chứng một phần đó trong một khung hợp nhất duy nhất.
tóm tắt
Phân loại ảnh đa nhãn là nhiệm vụ dự đoán một tập các nhãn tương ứng với các đối tượng, thuộc tính hoặc các thực thể khác hiện diện trong một ảnh. Trong công trình này, chúng tôi đề xuất Classification Transformer (C-Tran), một khung tổng quát cho phân loại ảnh đa nhãn tận dụng các Transformer để khai thác các phụ thuộc phức tạp giữa các đặc trưng thị giác và các nhãn. Phương pháp của chúng tôi bao gồm một bộ mã hóa Transformer được huấn luyện để dự đoán một tập các nhãn mục tiêu khi cho một tập đầu vào gồm các nhãn được che, và các đặc trưng thị giác từ một mạng nơ-ron tích chập. Một thành phần then chốt của phương pháp chúng tôi là một mục tiêu huấn luyện che nhãn (label mask) sử dụng một sơ đồ mã hóa ba trạng thái để biểu diễn trạng thái của các nhãn là dương, âm, hoặc chưa biết trong quá trình huấn luyện. Mô hình của chúng tôi cho thấy hiệu năng tốt nhất hiện nay trên các bộ dữ liệu thách thức như COCO và Visual Genome. Hơn nữa, bởi vì mô hình của chúng tôi biểu diễn một cách tường minh sự bất định của các nhãn trong quá trình huấn luyện, nó tổng quát hơn bằng cách cho phép chúng tôi tạo ra các kết quả được cải thiện cho các ảnh có chú thích nhãn một phần hoặc bổ sung trong quá trình suy luận. Chúng tôi minh họa khả năng bổ sung này trên các bộ dữ liệu ảnh COCO, Visual Genome, News500 và CUB.
chi tiết
trích dẫn
@inproceedings{lanchantin2021general,
title = {General Multi-label Image Classification with Transformers},
author = {Lanchantin, Jack and Wang, Tianlu and Ordonez, Vicente and Qi, Yanjun},
year = {2021},
booktitle = {Conference on Computer Vision and Pattern Recognition CVPR 2021},
url = {https://arxiv.org/abs/2011.14027},
}