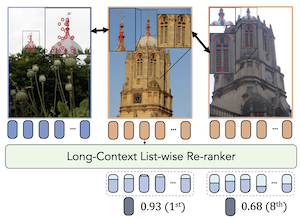
LoCoRe: Image Re-ranking with Long-Context Sequence Modeling
Tóm tắt thông cáo báo chí
Các nhà nghiên cứu từ Rice University và Czech Technical University in Prague đã phát triển một hệ thống truy hồi ảnh mới gọi là LOCORE, hệ thống này suy nghĩ lại cách các công cụ tìm kiếm thu hẹp và xếp hạng lại các ảnh ứng viên sau một lượt tìm kiếm rộng ban đầu. Các hệ thống xếp hạng lại truyền thống so sánh một ảnh truy vấn với từng ảnh ứng viên một cách riêng lẻ, mỗi lần một cặp, điều này có nghĩa là chúng bỏ lỡ các mối quan hệ hữu ích giữa chính các ảnh ứng viên với nhau — chẳng hạn, việc hai ảnh trong thư viện có thể chia sẻ các đặc trưng mà cùng nhau cung cấp bằng chứng mạnh hơn về một sự khớp. Thay vào đó, LOCORE xử lý truy vấn cùng với toàn bộ một danh sách ngắn lên đến 100 ảnh ứng viên đồng thời, sử dụng một mô hình transformer ngữ cảnh dài gọi là Longformer, ban đầu được phát triển cho các tài liệu văn bản dài, để nắm bắt những phụ thuộc chéo giữa các ảnh đó ở cấp độ các mô tả thị giác cục bộ tinh tế. Để xử lý các tình huống mà danh sách ngắn vượt quá những gì mô hình có thể chứa trong bộ nhớ cùng một lúc, nhóm đã thiết kế một chiến lược cửa sổ trượt di chuyển qua danh sách ứng viên theo các khối chồng lấn. Trong kiểm thử trên năm bộ dữ liệu benchmark bao gồm địa danh, sản phẩm, mặt hàng thời trang, và loài chim, LOCORE liên tục vượt trội hơn các phương pháp xếp hạng lại hiện có, bao gồm các cách tiếp cận theo cặp sử dụng mô tả cục bộ và các cách tiếp cận theo danh sách sử dụng mô tả toàn cục, trong khi chạy ở độ trễ tương đương hoặc thấp hơn và sử dụng ít bộ nhớ hơn đáng kể. Công trình có ý nghĩa vì việc xếp hạng lại tốt hơn trực tiếp cải thiện độ chính xác của các hệ thống tìm kiếm ảnh, và cách tiếp cận này chứng minh rằng các ý tưởng từ xử lý ngôn ngữ tự nhiên — đặc biệt là mô hình hóa ngữ cảnh dài và phân loại ở cấp độ token — có thể được chuyển giao một cách hiệu quả sang các tác vụ truy hồi thị giác.
tóm tắt
Chúng tôi giới thiệu LOCORE, Long-Context Re-ranker, một mô hình nhận đầu vào là các mô tả cục bộ tương ứng với một ảnh truy vấn và một danh sách các ảnh trong thư viện, rồi xuất ra điểm tương đồng giữa truy vấn và mỗi ảnh trong thư viện. Mô hình này được sử dụng cho truy hồi ảnh, trong đó một bước xếp hạng đầu tiên thường được thực hiện bằng một độ đo tương đồng hiệu quả, và sau đó một danh sách ngắn các ảnh xếp hạng cao nhất được xếp hạng lại dựa trên một độ đo tương đồng tinh tế hơn. So với các phương pháp hiện có thực hiện ước lượng tương đồng theo cặp với các mô tả cục bộ hoặc xếp hạng lại theo danh sách với các mô tả toàn cục, LOCORE là phương pháp đầu tiên thực hiện xếp hạng lại theo danh sách với các mô tả cục bộ. Để đạt được điều này, chúng tôi tận dụng các mô hình chuỗi ngữ cảnh dài hiệu quả nhằm nắm bắt một cách hữu hiệu các phụ thuộc giữa các ảnh truy vấn và thư viện ở cấp độ mô tả cục bộ. Trong quá trình kiểm thử, chúng tôi xử lý các danh sách ngắn dài bằng một chiến lược cửa sổ trượt được thiết kế riêng để khắc phục các giới hạn về kích thước ngữ cảnh của các mô hình chuỗi. Phương pháp của chúng tôi đạt được hiệu năng vượt trội so với các bộ xếp hạng lại khác trên các benchmark truy hồi ảnh đã được thiết lập về địa danh (ROxf và RPar), sản phẩm (SOP), mặt hàng thời trang (In-Shop), và loài chim (CUB-200) trong khi có độ trễ tương đương với các bộ xếp hạng lại mô tả cục bộ theo cặp.
chi tiết
trích dẫn
@inproceedings{xiao2025locore,
title = {LoCoRe: Image Re-ranking with Long-Context Sequence Modeling},
author = {Xiao, Zilin and Suma, Pavel and Sachdeva, Ayush and Wang, Hao-Jen and Kordopatis-Zilos, Giorgos and Tolias, Giorgos and Ordonez, Vicente},
year = {2025},
booktitle = {Conf. on Computer Vision and Pattern Recognition. CVPR 2025},
url = {https://arxiv.org/abs/2503.21772},
}
câu hỏi, đóng góp chính và hạn chế của bài báo này được tạo tự động
Câu hỏi mà bài báo này giúp trả lời
- LOCORE là gì và nó giải quyết vấn đề gì? LOCORE là một mô hình xếp hạng lại ảnh ngữ cảnh dài, xử lý đồng thời một ảnh truy vấn và một danh sách ngắn các ảnh trong thư viện bằng các mô tả cục bộ, cải thiện bước xếp hạng giai đoạn hai được sử dụng trong các hệ thống truy hồi ảnh.
- LOCORE khác với các bộ xếp hạng lại theo cặp như thế nào? Các phương pháp theo cặp so sánh truy vấn với từng ảnh trong thư viện một cách độc lập, trong khi LOCORE mô hình hóa toàn bộ danh sách ngắn cùng nhau để có thể khai thác các mối quan hệ giữa các ảnh trong thư viện cũng như các sự khớp truy vấn-thư viện.
- Tại sao LOCORE sử dụng một mô hình chuỗi ngữ cảnh dài? Việc xếp hạng lại đến 100 ảnh trong thư viện với các mô tả cục bộ tạo ra một chuỗi token dài, và cơ chế chú ý kiểu Longformer cho phép mô hình nắm bắt các phụ thuộc hữu ích với bộ nhớ và độ trễ có thể quản lý được.
- LOCORE xử lý các danh sách ngắn dài hơn cửa sổ ngữ cảnh của nó như thế nào? Nó sử dụng một chiến lược cửa sổ trượt chồng lấn, tái sử dụng bộ xếp hạng lại theo danh sách trên các phần của danh sách ngắn, cho phép phương pháp cải thiện các xếp hạng vượt ra ngoài kích thước danh sách tối đa thấy được trong một lượt truyền xuôi.
- LOCORE cải thiện những benchmark truy hồi nào? Bài báo báo cáo các kết quả xếp hạng lại dẫn đầu hoặc tốt nhất hiện nay trên các benchmark truy hồi địa danh, sản phẩm, thời trang, và loài chim, bao gồm ROxf/RPar, SOP, In-Shop, và CUB-200.
Đóng góp chính
- Bài báo giới thiệu khung làm việc xếp hạng lại ảnh theo danh sách đầu tiên hoạt động ở cấp độ mô tả cục bộ thay vì dựa vào khớp cục bộ theo cặp hoặc mô tả toàn cục theo danh sách.
- LOCORE định hình lại việc xếp hạng lại ảnh như một bài toán phân loại ở cấp độ token với ngữ cảnh dài, chuyển giao các ý tưởng từ trích xuất đoạn (span) trong NLP và gán nhãn chuỗi vào truy hồi thị giác.
- Mô hình sử dụng chú ý toàn cục cho truy vấn, các token phân tách, và huấn luyện xáo trộn thư viện để tránh các lối tắt theo vị trí và học các tương tác mô tả chéo giữa các ảnh có ý nghĩa.
- Trên ROxf/RPar và các biến thể có 1 triệu phần tử gây nhiễu của chúng, LOCORE cải thiện so với các bộ xếp hạng lại mô tả cục bộ trước đây như xác minh hình học, RRT, CVNet, và AMES dưới các thiết lập mô tả tương đương.
- Phương pháp cũng cải thiện các benchmark truy hồi Metric Learning bao gồm CUB-200, SOP, và In-Shop, cho thấy việc xếp hạng lại mô tả cục bộ theo danh sách là hữu ích vượt ra ngoài truy hồi địa danh.
Hạn chế và lưu ý
- LOCORE là một bộ xếp hạng lại giai đoạn hai chứ không phải là sự thay thế cho truy hồi giai đoạn một hiệu quả, điều này phù hợp với các quy trình tìm kiếm quy mô lớn nơi một mô tả toàn cục gọn nhẹ thu hẹp danh sách ứng viên trước.
- Phương pháp phụ thuộc vào các mô tả cục bộ chất lượng cao từ các hệ thống như DELG hoặc DINOv2, nhưng điều này khiến nó bổ trợ cho những tiến bộ trong trích xuất đặc trưng cục bộ thay vì gắn chặt với một backbone duy nhất.
- Việc xử lý ngữ cảnh dài có một cửa sổ ngữ cảnh hữu hạn, nên các danh sách ngắn rất dài đòi hỏi suy luận theo cửa sổ trượt; bài báo cho thấy chiến lược này hoạt động tốt và có thể mở rộng các lợi ích vượt ra ngoài kích thước danh sách huấn luyện.
- Việc huấn luyện đòi hỏi sự cẩn trọng để tránh các lối tắt theo vị trí từ xếp hạng toàn cục ban đầu, nhưng huấn luyện xáo trộn thư viện là một biện pháp khắc phục đơn giản và hiệu quả được chứng minh trong các nghiên cứu loại bỏ.
- Việc đánh giá tập trung vào các benchmark truy hồi ở cấp độ thực thể đã được thiết lập, để lại các thiết lập tìm kiếm sản xuất rộng hơn và các bộ sưu tập ảnh đặc thù theo lĩnh vực như những nghiên cứu triển khai tiếp theo tự nhiên.
Cách diễn giải kết quả này
Bài báo này được đọc tốt nhất như một đóng góp mạnh mẽ cho việc xếp hạng lại trong truy hồi ảnh: LOCORE cho thấy rằng mô hình hóa theo danh sách với ngữ cảnh dài có thể làm cho các mô tả cục bộ mạnh mẽ hơn, cải thiện độ chính xác trên các benchmark đa dạng trong khi vẫn giữ độ trễ và bộ nhớ ở mức thực tiễn cho truy hồi giai đoạn hai.