PropTest: Automatic Property Testing for Improved Visual Programming
新闻稿摘要
莱斯大学和哥伦比亚大学的研究人员开发了一种名为 PropTest 的方法,它通过编写计算机代码来提升求解视觉推理任务的 AI 系统的可靠性。这类“视觉编程”系统的工作方式是利用大语言模型生成回答有关图像问题的 Python 程序,例如识别物体或回答多步问题,但它们常常生成那种能够运行而不崩溃、却因逻辑缺陷而仍给出错误答案的代码。PropTest 借鉴了软件工程中的一个旧思想来应对这一问题:先写测试,再写代码。具体而言,该系统首先提示语言模型生成简短的测试用例,以检查答案的预期属性——例如,验证结果是一个字符串、长度为一到两个单词,以及当问题询问的是家电时它确实指出了某种家电类型。随后,在生成主求解代码时,这些测试会作为额外上下文反馈给模型,引导模型生成逻辑上更正确的程序。当生成的代码在运行时未通过这些测试时,系统会退回到一个标准的视觉-语言模型,而不是返回一个糟糕的答案。在涵盖视觉问答和物体定位的四个基准上进行测试,PropTest 在多个开源语言模型上始终优于基线 ViperGPT 系统,在 GQA 数据集上的提升高达 6 个百分点,在 RefCOCO+ 上高达 8 个百分点。值得注意的是,研究人员的主要实验使用的是 CodeLlama 和 Llama3 等可免费获取的模型,而非专有 API,从而解决了一个长期妨碍该研究领域比较的可复现性问题。
摘要
视觉编程(Visual Programming)近来作为端到端黑箱视觉推理模型的一种替代方案而出现。这类方法利用大语言模型(LLMs)生成可执行计算机程序的源代码,以求解给定的问题。这一策略的优势在于提供了可解释的推理路径,且无需用任务特定数据对模型进行微调。我们提出了 PropTest,这是一种通用策略,它通过进一步利用 LLM 生成代码来对初轮所提出解法中的视觉属性进行测试,从而改进视觉编程。我们的方法会为数据类型一致性、输出语法以及语义属性生成测试。PropTest 在使用公开可用的 LLM 的情况下取得了与最先进方法相当的结果。这一点在视觉问答和指代表达理解的不同基准上得到了验证。特别地,PropTest 改进了 ViperGPT:在使用 Llama3-8B 时于 GQA 上取得 46.1\% 的准确率(+6.0\%),在使用 CodeLlama-34B 时于 RefCOCO+ 上取得 59.5\%(+8.1\%)。
详情
引用
@inproceedings{koo2024proptest,
title = {PropTest: Automatic Property Testing for Improved Visual Programming},
author = {Koo, Jaywon and Yang, Ziyan and Cascante-Bonilla, Paola and Ray, Baishakhi and Ordonez, Vicente},
year = {2024},
booktitle = {Conf. on Empirical Methods in Natural Language Processing. EMNLP 2024},
url = {https://arxiv.org/abs/2403.16921},
}
自动生成的本文相关问题、主要贡献与局限
本文有助于回答的问题
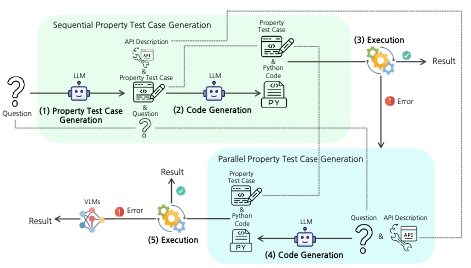
- 什么是 PropTest?PropTest 是一个视觉编程框架,它在为视觉推理任务生成可执行代码之前,先利用 LLM 生成属性测试。
- PropTest 解决了什么问题?它针对的是这样一些情形:生成的视觉程序没有语法或运行时错误地运行,却仍然返回逻辑上错误的答案。
- 属性测试如何改进视觉编程?这些测试将预期的答案属性(如数据类型、输出格式、语义类别或视觉属性)编码出来,进而引导代码生成并帮助检测无效输出。
- 本文评估了哪些任务?本文在 GQA 和 A-OKVQA 上评估视觉问答,并在 RefCOCO 和 RefCOCO+ 上评估视觉接地(visual grounding)。
- 为什么使用开源 LLM 很重要?本文强调使用 Llama3 和 CodeLlama 等模型进行可复现的视觉编程实验,从而减少对封闭或已弃用 API 模型的依赖。
主要贡献
- 本文将自动属性测试生成作为一种改进 LLM 生成的视觉程序的通用机制引入。
- PropTest 通过生成针对预期输出类型量身定制的测试,同时支持文本答案任务和边界框接地任务。
- 该方法在多个基准和 LLM 主干上改进了 ViperGPT,包括在使用 Llama3-8B 时于 GQA 上报告的 +6.0% 提升,以及在使用 CodeLlama-34B 时于 RefCOCO+ 上的 +8.1% 提升。
- 这项工作表明,生成的测试能够改善代码质量,而不仅仅是增加对作为后备的视觉-语言模型的依赖。
- 本文通过聚焦于公开可用的 LLM 和一条无需 API 的实现路径,为视觉编程贡献了一个更具可复现性的评估设置。
局限与注意事项
- PropTest 增加了一次额外的 LLM 调用来生成属性测试,但这是为换取更可靠的视觉程序而做出的实际权衡,并且随着更快的代码模型不断改进,其成本应会降低。
- 不同的输出类型需要不同的属性测试提示,这使实现保持显式,同时也指向一个明确的未来方向:按任务自动设计提示。
- 生成的属性测试本身可能包含错误,但本文分析了这一行为,并表明这些测试通常足够准确,能够改善端到端的结果。
- 该框架仍然依赖于生成程序所使用的视觉工具和 API 的质量,这使它与更好的工具构建和自我精炼方面的工作形成互补。
- 评估聚焦于基于图像的 VQA 和指代表达理解,这使得视频、时序和因果视觉推理成为有前景的下一步应用。
如何理解这一结果
这篇论文最好被理解为迈向更可靠视觉编程的一个强有力而务实的步骤:PropTest 将软件测试的思想引入多模态推理,在多个基准上改善了所生成程序的逻辑,并且是在使用公开 LLM 的可复现设置下做到这一点的。