新闻稿摘要
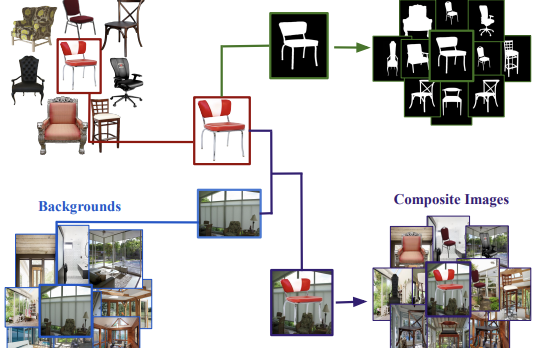
弗吉尼亚大学及合作机构的研究人员发布了一个名为 Chair Segments 的新数据集,旨在为计算机视觉科学家提供一种更快、更廉价的方式来测试图像分割算法。他们指出的核心问题是,现有的分割数据集——如 COCO 或 PASCAL VOC——规模庞大、标注成本高昂,并迫使模型同时处理对象识别、定位和像素级掩码,使得难以隔离并快速迭代针对分割的具体想法。为了绕开这一点,团队构建了一个半合成数据集,包含约 900 张带透明背景的椅子图像,合成到 10,000 张多样的室内外场景图像上,产生了 50,000 个训练合成图,并带有无需任何手工标注的像素级精确真值掩码。研究人员特意选择椅子:由于其细薄、中空和自遮挡的部件,该类别以难以分割而著称,并在现有基准中名列最难之一。他们的实验表明,一个 U-Net 模型可以在单块 GPU 上以 64×64 分辨率约 30 分钟训练至完全收敛——大致相当于分类领域 CIFAR-10 的复杂度水平——同时仍能有意义地区分更强和更弱的架构。重要的是,在 Chair Segments 上预训练并随后在无关的 Object Discovery 数据集(涵盖汽车、马和飞机)上微调的模型,在该基准上击败了所有此前发表的方法,表明该半合成数据捕捉到了真正有用的真实世界特征。团队还首次在分割领域证实了一种此前在图像分类中观察到的模式:从相同预训练权重微调的模型在优化地形中聚集在一起并平滑地相互过渡,而从随机初始化训练的模型则不会——这一发现对如何初始化和集成分割模型具有实际意义。
摘要
多年来,数据集和基准对新算法的设计产生了巨大的影响。在本文中,我们引入了 ChairSegments,一个新颖且紧凑的半合成对象分割数据集。我们还展示了迁移学习中的一些实证发现,这些发现与近期图像分类领域的发现相呼应。我们特别表明,从一组预训练权重微调得到的模型位于优化地形(optimization landscape)的同一盆地中。ChairSegments 由一组多样化的、具有透明背景的典型椅子图像组成,并合成到多样的背景之中。我们希望 ChairSegments 成为分割领域的 CIFAR-10 数据集,用于快速设计和迭代新颖的分割模型架构。在 Chair Segments 上,一个 U-Net 模型可以在单块 GPU 上仅用三十分钟训练至完全收敛。最后,尽管该数据集是半合成的,但它可以作为真实数据的有用代理,当用作预训练来源时,在 Object Discovery 数据集上取得了最先进的准确率。
详情
引用
@article{pintoalva2011chair,
title = {Chair Segments: A Compact Benchmark for the Study of Object Segmentation},
author = {Pinto-Alva, Leticia and Torres, Ian K. and Garcia, Rosangel and Yang, Ziyan and Ordonez, Vicente},
year = {2011},
journal = {arxiv:2011.14027 Nov 2020.},
url = {https://arxiv.org/abs/2012.01250},
}