Learning from Synthetic Data for Visual Grounding
Zusammenfassung der Pressemitteilung
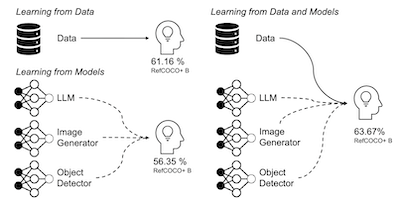
Forschende an der Rice University, der University of Maryland und der UC Irvine haben eine Pipeline namens SynGround entwickelt, die automatisch große Mengen synthetischer Trainingsdaten generiert, um KI-Systemen zu helfen, Textbeschreibungen besser mit bestimmten Regionen innerhalb von Bildern zu verbinden — eine Aufgabe, die als visuelles Grounding bekannt ist. Die Herausforderung, der sie sich annahmen, besteht darin, dass Bild-Text-Paare zwar in großem Umfang aus dem Web gesammelt werden können, die für das Grounding benötigten Annotationen auf Regionenebene (Begrenzungsrahmen, die Phrasen mit Bildbereichen verknüpfen) jedoch teuer und langsam von Hand zu erstellen sind; der Visual-Genome-Datensatz, ein Standard-Benchmark, benötigte 33.000 Arbeitskräfte und sechs Monate für seine Erstellung. SynGround umgeht diesen Engpass, indem es mehrere bestehende vortrainierte Modelle aneinanderreiht: Ein großes multimodales Modell (LLaVA) beschriftet reale Bilder detailliert, diese Beschreibungen werden einem Text-zu-Bild-Generator (Stable Diffusion) zugeführt, um synthetische Bilder zu erstellen, ein LLM (Vicuna) extrahiert kurze Nominalphrasen aus den Bildunterschriften, und ein Objektdetektor mit offenem Vokabular (GLIP) zeichnet Begrenzungsrahmen um die referenzierten Objekte in den synthetischen Bildern. Durch systematische Experimente stellte das Team fest, dass detaillierte Bildunterschriften weitaus bessere synthetische Bilder für diese Aufgabe erzeugen als einfache Textverkettung oder von einem LLM generierte Zusammenfassungen und dass kürzere extrahierte Phrasen besser funktionieren als längere. Bei der Verwendung zum Feinabstimmen zweier gebrauchsfertiger Vision-Language-Modelle, ALBEF und BLIP, verbesserte SynGround die Lokalisierungsgenauigkeit über die Benchmarks RefCOCO+ und Flickr30k hinweg um 4,81 bzw. 17,11 Prozentpunkte; die Kombination der synthetischen Daten mit realen annotierten Daten steigerte die Leistung noch weiter und übertraf den bisherigen Stand der Technik. Die Arbeit zeigte zudem, dass der Ansatz mit minimaler Abhängigkeit von realen Bildern funktionieren kann und mit mehr Daten günstig skaliert, was nahelegt, dass automatisierte synthetische Pipelines zu einem praktischen Ersatz für kostspielige menschliche Annotation beim Training von Grounding-Systemen werden könnten.
Zusammenfassung
Diese Arbeit untersucht umfassend die Wirksamkeit synthetischer Trainingsdaten zur Verbesserung der Fähigkeiten von Vision-and-Language-Modellen, textuelle Beschreibungen mit Bildregionen zu verankern. Wir erkunden verschiedene Strategien, um Bild-Text-Paare und Bild-Text-Box-Tripel mithilfe einer Reihe vortrainierter Modelle unter unterschiedlichen Einstellungen und mit variierendem Maß an Abhängigkeit von realen Daten bestmöglich zu generieren. Durch vergleichende Analysen mit synthetischen, realen und aus dem Web gesammelten Daten identifizieren wir Faktoren, die zu Leistungsunterschieden beitragen, und schlagen SynGround vor, eine effektive Pipeline zur Generierung nützlicher synthetischer Daten für das visuelle Grounding. Unsere Ergebnisse zeigen, dass SynGround die Lokalisierungsfähigkeiten von gebrauchsfertigen Vision-and-Language-Modellen verbessern kann und das Potenzial für eine beliebig groß angelegte Datengenerierung bietet. Insbesondere verbessern mit SynGround generierte Daten die Pointing-Game-Genauigkeit eines vortrainierten ALBEF- und BLIP-Modells um 4,81 % bzw. 17,11 % absolute Prozentpunkte über die Benchmarks RefCOCO+ und Flickr30k hinweg.
Details
Zitation
@inproceedings{he2025learning,
title = {Learning from Synthetic Data for Visual Grounding},
author = {He, Ruozhen and Cascante-Bonilla, Paola and Yang, Ziyan and Berg, Alexander C. and Ordonez, Vicente},
year = {2025},
booktitle = {British Machine Vision Conference. BMVC 2025},
url = {https://arxiv.org/abs/2403.13804},
}
automatisch generierte Fragen, wichtigste Beiträge und Grenzen dieses Artikels
Fragen, die dieser Artikel beantworten hilft
- Was ist SynGround und welches Problem adressiert es? SynGround ist eine Pipeline für synthetische Daten zum visuellen Grounding, die Bild-Text-Box-Tripel generiert, um die Abhängigkeit von teuren menschlichen Regionen-Annotationen zu verringern.
- Wie generiert SynGround Trainingsdaten? Es verwendet ein Bildbeschreibungsmodell, um detaillierte Bildunterschriften zu erzeugen, einen Text-zu-Bild-Generator, um Bilder zu synthetisieren, ein LLM, um kurze Grounding-Phrasen zu extrahieren, und einen Detektor mit offenem Vokabular, um Boxen für diese Phrasen zu erzeugen.
- Warum sind detaillierte Bildunterschriften in der Pipeline wichtig? Die Experimente zeigen, dass detaillierte Image2Text-Bildunterschriften nützlichere synthetische Bilder für das Grounding erzeugen als einfache Verkettung von Bildunterschriften oder Text2Text-Zusammenfassungen.
- Wie stark verbessert SynGround das visuelle Grounding? Synthetische Daten von SynGround verbessern ALBEF im Durchschnitt um 4,81 Prozentpunkte und BLIP um 17,11 Prozentpunkte über die Pointing-Game-Bewertungen von RefCOCO+ und Flickr30k hinweg.
- Kann SynGround die Abhängigkeit von realen Bildern verringern? Ja, die Arbeit berichtet über Varianten mit deutlich geringerer Abhängigkeit von realen Bildern und zeigt, dass synthetische Daten beim visuellen Grounding vergleichbare, aus dem Web gesammelte Daten übertreffen.
Wichtigste Beiträge
- Die Arbeit liefert eine systematische Studie darüber, wie nützliche Bild-Text- und Bild-Text-Box-Daten für das visuelle Grounding synthetisiert werden, anstatt nur ein einziges Rezept für synthetische Daten zu demonstrieren.
- SynGround kombiniert leistungsstarke vortrainierte Modelle für Beschriftung, Bildgenerierung, Phrasenextraktion und Detektion mit offenem Vokabular zu einer praktischen Pipeline für skalierbare Grounding-Supervision.
- Die Experimente identifizieren konkrete Designentscheidungen, die wichtig sind, einschließlich detaillierter Bildbeschreibungen für die Generierung und kürzerer extrahierter Phrasen für die Grounding-Supervision.
- Die Arbeit zeigt, dass synthetische Tripel zwei verschiedene Vision-Language-Modelle, ALBEF und BLIP, verbessern können, was die Allgemeingültigkeit des Ansatzes über eine einzige Architektur hinaus stützt.
- Der Vergleich mit aus dem Web gesammelten Conceptual-Captions-Daten zeigt, dass gezielte synthetische Daten für das Grounding effektiver sein können als das bloße Skalieren generischer Bild-Text-Daten.
Grenzen und Vorbehalte
- SynGround erbt einige Einschränkungen von den vortrainierten Beschriftungsmodellen, Bildgeneratoren, LLMs und Detektoren, die es verwendet, aber das bedeutet auch, dass sich die Pipeline auf natürliche Weise verbessern kann, wenn diese Komponentenmodelle stärker werden.
- Synthetische Boxen und Bildunterschriften erreichen nicht vollständig die Präzision und Vielfalt menschlicher Visual-Genome-Annotationen, doch die Leistungsgewinne zeigen, dass sie bereits nützlich genug sind, um den Annotationsdruck erheblich zu verringern.
- Einige generierte Personen oder Szenen können visuelle Artefakte enthalten, was ein bekanntes Problem der synthetischen Bildgenerierung ist; die Grounding-Verbesserungen legen nahe, dass die Pipeline trotz gelegentlich unvollkommener Stichproben effektiv bleibt.
- Die Studie konzentriert sich hauptsächlich auf visuelles Grounding im Pointing-Game-Stil mit ALBEF und BLIP und lässt Systeme zur Phrasen-Box-Vorhersage und neuere multimodale Architekturen als vielversprechende Folgeziele offen.
- Die Pipeline hat mehrere Stufen und Designentscheidungen, aber die Ablationen der Arbeit machen diese Entscheidungen interpretierbar und liefern ein starkes praktisches Rezept für zukünftige synthetische Grounding-Datensätze.
Wie dieses Ergebnis zu lesen ist
Diese Arbeit lässt sich am besten als ein starkes empirisches Argument für synthetische Supervision beim visuellen Grounding lesen: SynGround zeigt, dass sorgfältig generierte Bild-Text-Box-Tripel die Lokalisierung deutlich verbessern, reale Daten ergänzen und einen skalierbaren Weg jenseits teurer menschlicher Regionen-Annotation bieten können.