Learning from Synthetic Data for Visual Grounding
Краткое изложение пресс-релиза
Исследователи из Rice University, University of Maryland и UC Irvine разработали конвейер под названием SynGround, который автоматически генерирует большие объёмы синтетических обучающих данных, чтобы помочь AI-системам лучше связывать текстовые описания с конкретными областями изображений — задача, известная как визуальная локализация. Проблема, которую они решали, состоит в том, что хотя пары изображение-текст можно собирать из веба в больших масштабах, аннотации уровня областей, необходимые для локализации (ограничивающие рамки, связывающие фразы с участками изображения), дороги и медленны в ручном создании; набор данных Visual Genome, стандартный бенчмарк, потребовал 33 000 работников и шести месяцев на построение. SynGround обходит это узкое место, объединяя в цепочку несколько существующих предобученных моделей: крупная мультимодальная модель (LLaVA) детально подписывает реальные изображения, эти описания подаются в генератор изображений из текста (Stable Diffusion) для создания синтетических изображений, LLM (Vicuna) извлекает короткие именные группы из подписей, а детектор объектов с открытым словарём (GLIP) рисует ограничивающие рамки вокруг упомянутых объектов на синтетических изображениях. Через систематические эксперименты команда обнаружила, что детальные подписи к изображениям дают гораздо более качественные синтетические изображения для этой задачи, чем простая конкатенация текста или сгенерированные LLM резюме, и что более короткие извлечённые фразы работают лучше длинных. При использовании для дообучения двух готовых моделей зрения и языка, ALBEF и BLIP, SynGround улучшил точность локализации на 4.81 и 17.11 процентных пункта соответственно на бенчмарках RefCOCO+ и Flickr30k; объединение синтетических данных с реальными аннотированными данными подняло качество ещё выше, превзойдя прежний современный уровень. Работа также показала, что подход может функционировать с минимальной опорой на реальные изображения и благоприятно масштабируется с увеличением объёма данных, что говорит о том, что автоматизированные синтетические конвейеры могут стать практичной заменой дорогостоящей человеческой разметке при обучении систем локализации.
аннотация
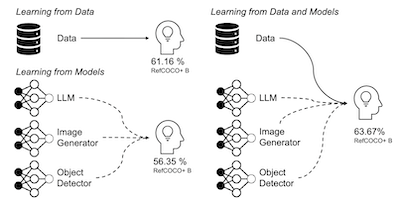
В этой статье подробно исследуется эффективность синтетических обучающих данных для улучшения способностей моделей зрения и языка локализовать текстовые описания по областям изображения. Мы изучаем различные стратегии оптимальной генерации пар изображение-текст и триплетов изображение-текст-рамка с использованием ряда предобученных моделей в разных условиях и с разной степенью опоры на реальные данные. Через сравнительный анализ синтетических, реальных и собранных из веба данных мы выявляем факторы, способствующие различиям в качестве, и предлагаем SynGround — эффективный конвейер для генерации полезных синтетических данных для визуальной локализации. Наши результаты показывают, что SynGround может улучшить способности к локализации у готовых моделей зрения и языка и открывает потенциал для генерации данных произвольно большого масштаба. В частности, данные, сгенерированные с помощью SynGround, улучшают точность pointing game у предобученных моделей ALBEF и BLIP на 4.81% и 17.11% абсолютных процентных пункта соответственно на бенчмарках RefCOCO+ и Flickr30k.
подробности
цитирование
@inproceedings{he2025learning,
title = {Learning from Synthetic Data for Visual Grounding},
author = {He, Ruozhen and Cascante-Bonilla, Paola and Yang, Ziyan and Berg, Alexander C. and Ordonez, Vicente},
year = {2025},
booktitle = {British Machine Vision Conference. BMVC 2025},
url = {https://arxiv.org/abs/2403.13804},
}
автоматически сгенерированные вопросы, основные вклады и ограничения этой статьи
Вопросы, на которые помогает ответить эта статья
- Что такое SynGround и какую проблему он решает? SynGround — это конвейер синтетических данных для визуальной локализации, который генерирует триплеты изображение-текст-рамка, чтобы снизить зависимость от дорогостоящих человеческих аннотаций областей.
- Как SynGround генерирует обучающие данные? Он использует модель описания изображений для создания детальных подписей, генератор изображений из текста для синтеза изображений, LLM для извлечения коротких фраз локализации и детектор с открытым словарём для построения рамок для этих фраз.
- Почему детальные подписи важны в конвейере? Эксперименты показывают, что детальные подписи Image2Text дают более полезные синтетические изображения для локализации, чем простая конкатенация подписей или резюме Text2Text.
- Насколько SynGround улучшает визуальную локализацию? Синтетические данные от SynGround улучшают ALBEF на 4.81 процентных пункта и BLIP на 17.11 процентных пункта в среднем по оценкам pointing-game на RefCOCO+ и Flickr30k.
- Может ли SynGround снизить зависимость от реальных изображений? Да, в статье представлены варианты с гораздо меньшей опорой на реальные изображения и показано, что синтетические данные превосходят сопоставимые собранные из веба данные для визуальной локализации.
Основные вклады
- Статья предоставляет систематическое исследование того, как синтезировать полезные данные изображение-текст и изображение-текст-рамка для визуальной локализации, а не просто демонстрирует один рецепт синтетических данных.
- SynGround объединяет сильные предобученные модели для подписывания, генерации изображений, извлечения фраз и детекции с открытым словарём в практичный конвейер для масштабируемой супервизии локализации.
- Эксперименты выявляют конкретные значимые проектные решения, включая детальные описания изображений для генерации и более короткие извлечённые фразы для супервизии локализации.
- Статья показывает, что синтетические триплеты могут улучшить две разные модели зрения и языка, ALBEF и BLIP, подтверждая универсальность подхода за пределами одной архитектуры.
- Сравнение с собранными из веба данными Conceptual Captions показывает, что целенаправленные синтетические данные могут быть более эффективными для локализации, чем простое масштабирование универсальных данных изображение-текст.
Ограничения и предостережения
- SynGround наследует некоторые ограничения от используемых им предобученных моделей подписывания, генераторов изображений, LLM и детекторов, но это также означает, что конвейер может естественным образом улучшаться по мере усиления этих компонентных моделей.
- Синтетические рамки и подписи не полностью соответствуют точности и разнообразию человеческих аннотаций Visual Genome, однако прирост качества показывает, что они уже достаточно полезны, чтобы существенно снизить нагрузку по разметке.
- Некоторые сгенерированные люди или сцены могут содержать визуальные артефакты, что является известной проблемой синтетической генерации изображений; улучшения локализации говорят о том, что конвейер остаётся эффективным несмотря на отдельные несовершенные сэмплы.
- Исследование сосредоточено в основном на визуальной локализации в стиле pointing-game с ALBEF и BLIP, оставляя системы предсказания фраза-рамка и более новые мультимодальные архитектуры перспективными целями для продолжения.
- Конвейер имеет несколько стадий и проектных решений, но абляции в статье делают эти решения интерпретируемыми и предоставляют сильный практический рецепт для будущих синтетических наборов данных для локализации.
Как интерпретировать этот результат
Эту статью лучше всего воспринимать как сильное эмпирическое обоснование синтетической супервизии в визуальной локализации: SynGround показывает, что тщательно сгенерированные триплеты изображение-текст-рамка могут заметно улучшить локализацию, дополнить реальные данные и предложить масштабируемый путь за пределы дорогостоящей человеческой разметки областей.