Learning from Synthetic Data for Visual Grounding
プレスリリース要約
Rice大学、メリーランド大学、UC Irvineの研究者らは、AIシステムがテキスト記述を画像内の特定の領域により適切に結びつけるのを助ける、つまり視覚的グラウンディングとして知られるタスクのために、大量の合成学習データを自動的に生成するSynGroundと呼ばれるパイプラインを開発しました。彼らが取り組んだ課題は、画像テキストペアはウェブから大規模にスクレイピングできる一方、グラウンディングに必要な領域レベルのアノテーション(フレーズを画像領域に結びつけるバウンディングボックス)は高コストで手作業での作成に時間がかかることです。標準的なベンチマークであるVisual Genomeデータセットの構築には、33,000人の作業者で6か月を要しました。SynGroundは、いくつかの既存の事前学習済みモデルを連鎖させることでこのボトルネックを回避します。すなわち、大規模マルチモーダルモデル(LLaVA)が実画像を詳細にキャプショニングし、それらの記述がテキストから画像への生成器(Stable Diffusion)に入力されて合成画像を作成し、LLM(Vicuna)がキャプションから短い名詞句を抽出し、オープン語彙物体検出器(GLIP)が合成画像内の参照された物体の周りにバウンディングボックスを描きます。体系的な実験を通じて、チームは、詳細な画像キャプションが、単純なテキスト連結やLLM生成の要約よりも、このタスクにとってはるかに優れた合成画像を生成すること、そして抽出されたフレーズは長いものよりも短いものの方がうまく機能することを発見しました。既製の2つの視覚言語モデルALBEFとBLIPのファインチューニングに使用すると、SynGroundはRefCOCO+とFlickr30kのベンチマークにわたって位置特定精度をそれぞれ4.81および17.11パーセントポイント向上させました。合成データを実際のアノテーション付きデータと組み合わせると性能はさらに高まり、以前の最先端を上回りました。本研究はまた、このアプローチが実画像への依存を最小限に抑えて機能でき、より多くのデータとともに良好にスケールすることも示し、自動化された合成パイプラインが、グラウンディングシステムの学習における高コストな人間によるアノテーションの実用的な代替手段になり得ることを示唆しています。
要旨
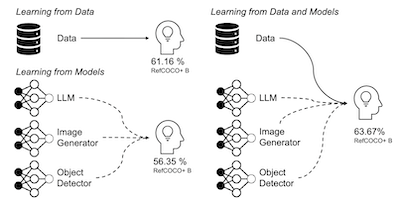
本論文は、テキスト記述を画像領域にグラウンディングするための視覚言語モデルの能力を向上させる、合成学習データの有効性を広範に調査します。私たちは、さまざまな設定および実データへの依存度を変化させながら、一連の事前学習済みモデルを使用して画像テキストペアおよび画像テキストボックス三つ組を最適に生成するための多様な戦略を探求します。合成データ、実データ、ウェブクロールデータとの比較分析を通じて、性能差に寄与する要因を特定し、視覚的グラウンディングのための有用な合成データを生成する効果的なパイプラインであるSynGroundを提案します。私たちの知見は、SynGroundが既製の視覚言語モデルの位置特定能力を向上させ、任意の大規模なデータ生成の可能性を提供することを示しています。特に、SynGroundで生成されたデータは、RefCOCO+およびFlickr30kベンチマークにわたって、事前学習済みのALBEFおよびBLIPモデルのpointing game精度をそれぞれ4.81%および17.11%の絶対パーセントポイント向上させます。
詳細
引用
@inproceedings{he2025learning,
title = {Learning from Synthetic Data for Visual Grounding},
author = {He, Ruozhen and Cascante-Bonilla, Paola and Yang, Ziyan and Berg, Alexander C. and Ordonez, Vicente},
year = {2025},
booktitle = {British Machine Vision Conference. BMVC 2025},
url = {https://arxiv.org/abs/2403.13804},
}
この論文について自動生成された質問、主な貢献、および限界
この論文が答える助けとなる質問
- SynGroundとは何で、どのような問題に取り組んでいるのか。SynGroundは、高コストな人間による領域アノテーションへの依存を減らすために画像テキストボックス三つ組を生成する、視覚的グラウンディングのための合成データパイプラインです。
- SynGroundはどのようにして学習データを生成するのか。画像記述モデルを使用して詳細なキャプションを生成し、テキストから画像への生成器を使用して画像を合成し、LLMを使用して短いグラウンディングフレーズを抽出し、オープン語彙検出器を使用してそれらのフレーズに対するボックスを生成します。
- 詳細なキャプションはなぜパイプラインにおいて重要なのか。実験は、詳細なImage2Textキャプションが、単純なキャプション連結やText2Textの要約よりも、グラウンディングにとってより有用な合成画像を生成することを示しています。
- SynGroundは視覚的グラウンディングをどの程度向上させるのか。SynGroundからの合成データは、RefCOCO+とFlickr30kのpointing-game評価にわたって平均して、ALBEFを4.81パーセントポイント、BLIPを17.11パーセントポイント向上させます。
- SynGroundは実画像への依存を減らせるのか。はい、論文は実画像への依存がはるかに少ないバリアントを報告しており、合成データが視覚的グラウンディングにおいて同等のウェブクロールデータを上回ることを示しています。
主な貢献
- 本論文は、単一の合成データレシピを実証するだけでなく、視覚的グラウンディングのための有用な画像テキストおよび画像テキストボックスのデータをどのように合成するかについての体系的な研究を提供します。
- SynGroundは、キャプショニング、画像生成、フレーズ抽出、オープン語彙検出のための強力な事前学習済みモデルを、スケーラブルなグラウンディング教師信号のための実用的なパイプラインに組み合わせます。
- 実験は、生成のための詳細な画像記述やグラウンディング教師信号のためのより短い抽出フレーズを含め、重要となる具体的な設計の選択を特定します。
- 本論文は、合成三つ組がALBEFとBLIPという2つの異なる視覚言語モデルを向上させ得ることを示し、本アプローチが単一のアーキテクチャを超えて一般性を持つことを裏付けています。
- Conceptual Captionsのウェブクロールデータとの比較は、的を絞った合成データが、単に汎用的な画像テキストデータをスケールさせるよりもグラウンディングにとって効果的であり得ることを示しています。
限界と注意点
- SynGroundは、使用する事前学習済みのキャプショナー、画像生成器、LLM、検出器からいくつかの限界を引き継ぎますが、それはまた、それらの構成モデルがより強力になるにつれてパイプラインが自然に改善できることを意味します。
- 合成ボックスとキャプションは、人間によるVisual Genomeアノテーションの精度と多様性に完全には一致しませんが、性能の向上は、それらがアノテーションの負担を大幅に軽減するのにすでに十分有用であることを示しています。
- 生成された一部の人物やシーンには視覚的なアーティファクトが含まれる場合があり、これは合成画像生成における既知の問題です。グラウンディングの改善は、時折不完全なサンプルがあるにもかかわらずパイプラインが依然として効果的であることを示唆しています。
- 本研究は主にALBEFとBLIPを用いたpointing-gameスタイルの視覚的グラウンディングに焦点を当てており、フレーズボックス予測システムやより新しいマルチモーダルアーキテクチャは有望な後続の対象として残されています。
- パイプラインには複数の段階と設計の選択がありますが、論文のアブレーション研究はそれらの選択を解釈可能にし、今後の合成グラウンディングデータセットのための強力な実用的レシピを提供します。
この結果の読み解き方
本論文は、視覚的グラウンディングにおける合成教師信号の強力な実証的事例として読むのが最も適切です。SynGroundは、慎重に生成された画像テキストボックス三つ組が位置特定を意味のある形で向上させ、実データを補強し、高コストな人間による領域アノテーションを超えるスケーラブルな道筋を提供できることを示しています。