FlexEControl: Flexible and Efficient Multimodal Control for Text-to-Image Generation
Résumé du communiqué de presse
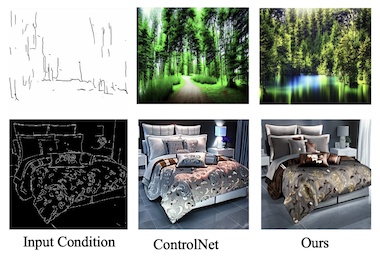
Des chercheurs de l'UC Santa Cruz, d'Amazon, de l'UNC Chapel Hill, de l'université Rice et de l'UCLA ont mis au point une manière plus efficace de contrôler les générateurs d'images par IA en utilisant simultanément plusieurs types de guidage visuel. Les modèles de diffusion texte-vers-image actuels comme Stable Diffusion peuvent être pilotés par des entrées structurelles telles que des cartes de contours, des cartes de profondeur et des cartes de segmentation, mais l'entraînement de ces systèmes contrôlables exige généralement des ressources computationnelles importantes qui augmentent linéairement à mesure que davantage de types d'entrées sont ajoutés. Le nouveau système de l'équipe, appelé FlexEControl, aborde ce problème en empruntant une technique mathématique appelée décomposition de Kronecker à la littérature plus large de l'apprentissage automatique, l'utilisant pour créer un ensemble compact de poids partagés qui gère différentes modalités d'entrée plutôt que d'apprendre des paramètres distincts pour chacune. Le résultat est un modèle qui utilise 41 % de paramètres entraînables en moins et 30 % de mémoire en moins qu'un système comparable de premier plan appelé UniControlNet, tout en réduisant le temps d'entraînement par itération d'environ 5,7 secondes à 2,1 secondes. Au-delà de l'efficacité brute, FlexEControl obtient également de meilleures performances lorsqu'il jongle avec plusieurs entrées conflictuelles ou redondantes — par exemple, deux cartes de contours différentes de la même scène — un scénario où les méthodes existantes tendent à produire des images confuses ou incohérentes. Les chercheurs y sont parvenus en ajoutant deux fonctions de perte d'entraînement spécialisées qui forcent le modèle à prêter attention aux bonnes régions spatiales et à aligner ses sorties sur les invites textuelles correspondantes. Lors d'évaluations humaines, les annotateurs ont préféré les sorties de FlexEControl 64 % du temps à celles d'UniControlNet lorsque les deux systèmes recevaient plusieurs entrées du même type. Ce travail importe car rendre la génération d'images contrôlable moins coûteuse et plus apte à gérer des entrées complexes et mixtes pourrait élargir de manière significative l'accès à ces outils pour les développeurs et chercheurs travaillant avec des ressources de calcul limitées.
résumé
Les modèles de diffusion texte-vers-image (T2I) contrôlables génèrent des images conditionnées à la fois par des invites textuelles et par des entrées sémantiques d'autres modalités telles que les cartes de contours. Néanmoins, les méthodes T2I contrôlables actuelles rencontrent fréquemment des difficultés liées à l'efficacité et à la fidélité, en particulier lors d'un conditionnement sur plusieurs entrées issues d'une même modalité ou de modalités diverses. Dans cet article, nous proposons une nouvelle méthode flexible et efficace, FlexEControl, pour la génération T2I contrôlable. Au cœur de FlexEControl se trouve une stratégie unique de décomposition des poids, qui permet une intégration rationalisée de divers types d'entrées. Cette approche améliore non seulement la fidélité de l'image générée au contrôle, mais réduit aussi significativement le surcoût computationnel généralement associé au conditionnement multimodal. Notre approche obtient une réduction de 41 % des paramètres entraînables et de 30 % de l'utilisation de la mémoire par rapport à Uni-ControlNet. De plus, elle double l'efficacité des données et peut générer de manière flexible des images sous le guidage de multiples conditions d'entrée de diverses modalités.
citation
@article{he2025flexecontrol,
title = {FlexEControl: Flexible and Efficient Multimodal Control for Text-to-Image Generation},
author = {He, Xuehai and Zheng, Jian and Fang, Jacob Zhiyuan and Piramuthu, Robinson and Bansal, Mohit and Ordonez, Vicente and Sigurdsson, Gunnar A and Peng, Nanyun and Wang, Xin Eric},
year = {2025},
journal = {Transactions of Machine Learning Research, TMLR 2025.},
url = {https://arxiv.org/abs/2405.04834},
}