FlexEControl: Flexible and Efficient Multimodal Control for Text-to-Image Generation
Краткое изложение пресс-релиза
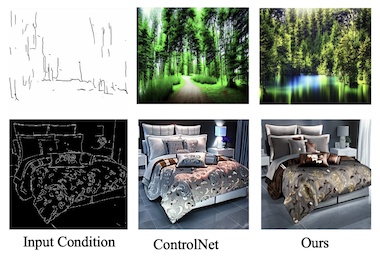
Исследователи из UC Santa Cruz, Amazon, UNC Chapel Hill, Rice University и UCLA разработали более эффективный способ управления генераторами изображений на основе искусственного интеллекта с использованием нескольких типов визуального управления одновременно. Современные диффузионные модели генерации изображений из текста, такие как Stable Diffusion, могут управляться структурными входными данными, такими как карты границ, карты глубины и карты сегментации, но обучение этих управляемых систем обычно требует значительных вычислительных ресурсов, которые растут линейно по мере добавления новых типов входных данных. Новая система команды под названием FlexEControl решает эту проблему, заимствуя математическую технику под названием разложение Кронекера из более широкой литературы по машинному обучению и используя её для создания компактного набора общих весов, который обрабатывает различные входные модальности, вместо обучения отдельных параметров для каждой из них. В результате получается модель, которая использует на 41% меньше обучаемых параметров и на 30% меньше памяти, чем ведущая сопоставимая система под названием UniControlNet, при этом сокращая время обучения на итерацию примерно с 5,7 до 2,1 секунды. Помимо чистой эффективности, FlexEControl также лучше работает при обработке нескольких конфликтующих или избыточных входных данных — например, двух разных карт границ одной и той же сцены — в сценарии, где существующие методы склонны производить нечёткие или несогласованные изображения. Исследователи добились этого, добавив две специализированные функции потерь при обучении, которые заставляют модель обращать внимание на правильные пространственные области и согласовывать свои выходные данные с соответствующими текстовыми запросами. В оценках с участием людей аннотаторы предпочитали выходные данные FlexEControl в 64% случаев по сравнению с UniControlNet, когда обеим системам подавалось несколько входных данных одного типа. Эта работа важна, поскольку удешевление управляемой генерации изображений и повышение её способности обрабатывать сложные, смешанные входные данные могло бы существенно расширить доступ к этим инструментам для разработчиков и исследователей, работающих с ограниченными вычислительными ресурсами.
аннотация
Управляемые диффузионные модели генерации изображений из текста (T2I) создают изображения, обусловленные как текстовыми запросами, так и семантическими входными данными других модальностей, такими как карты границ. Тем не менее современные управляемые T2I-методы обычно сталкиваются с проблемами, связанными с эффективностью и точностью соответствия, особенно при обусловливании несколькими входными данными из одной и той же или различных модальностей. В этой статье мы предлагаем новый гибкий и эффективный метод FlexEControl для управляемой генерации T2I. В основе FlexEControl лежит уникальная стратегия декомпозиции весов, которая обеспечивает упрощённую интеграцию различных типов входных данных. Этот подход не только повышает точность соответствия сгенерированного изображения управляющему сигналу, но и значительно снижает вычислительные накладные расходы, обычно связанные с мультимодальным обусловливанием. Наш подход достигает сокращения на 41% обучаемых параметров и на 30% использования памяти по сравнению с Uni-ControlNet. Более того, он удваивает эффективность использования данных и может гибко генерировать изображения под управлением нескольких входных условий различных модальностей.
цитирование
@article{he2025flexecontrol,
title = {FlexEControl: Flexible and Efficient Multimodal Control for Text-to-Image Generation},
author = {He, Xuehai and Zheng, Jian and Fang, Jacob Zhiyuan and Piramuthu, Robinson and Bansal, Mohit and Ordonez, Vicente and Sigurdsson, Gunnar A and Peng, Nanyun and Wang, Xin Eric},
year = {2025},
journal = {Transactions of Machine Learning Research, TMLR 2025.},
url = {https://arxiv.org/abs/2405.04834},
}