FlexEControl: Flexible and Efficient Multimodal Control for Text-to-Image Generation
Sintesi del comunicato stampa
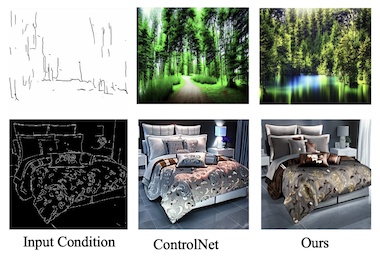
I ricercatori di UC Santa Cruz, Amazon, UNC Chapel Hill, Rice University e UCLA hanno sviluppato un modo più efficiente di controllare i generatori di immagini basati su IA utilizzando simultaneamente molteplici tipi di guida visiva. Gli attuali modelli di diffusione text-to-image come Stable Diffusion possono essere guidati da input strutturali come mappe dei contorni, mappe di profondità e mappe di segmentazione, ma l'addestramento di questi sistemi controllabili richiede tipicamente risorse computazionali sostanziali che crescono linearmente man mano che vengono aggiunti più tipi di input. Il nuovo sistema del team, chiamato FlexEControl, affronta questo problema prendendo in prestito una tecnica matematica chiamata decomposizione di Kronecker dalla più ampia letteratura del machine learning, utilizzandola per creare un insieme compatto di pesi condivisi che gestisce diverse modalità di input anziché apprendere parametri separati per ciascuna di esse. Il risultato è un modello che utilizza il 41% in meno di parametri addestrabili e il 30% in meno di memoria rispetto a un sistema comparabile di primo piano chiamato UniControlNet, riducendo al contempo il tempo di addestramento per iterazione da circa 5,7 secondi a 2,1 secondi. Oltre alla pura efficienza, FlexEControl si comporta anche meglio quando deve gestire molteplici input contrastanti o ridondanti — ad esempio, due diverse mappe dei contorni della stessa scena — uno scenario in cui i metodi esistenti tendono a produrre immagini confuse o incoerenti. I ricercatori hanno ottenuto questo aggiungendo due funzioni di loss di addestramento specializzate che costringono il modello a prestare attenzione alle giuste regioni spaziali e ad allineare i propri output con i corrispondenti prompt testuali. Nelle valutazioni umane, gli annotatori hanno preferito gli output di FlexEControl il 64% delle volte rispetto a quelli di UniControlNet quando a entrambi i sistemi venivano forniti molteplici input dello stesso tipo. Il lavoro è importante perché rendere la generazione di immagini controllabile più economica e più capace di gestire input complessi e misti potrebbe ampliare in modo significativo l'accesso a questi strumenti per sviluppatori e ricercatori che lavorano con risorse di calcolo limitate.
abstract
I modelli di diffusione controllabili text-to-image (T2I) generano immagini condizionate sia da prompt testuali sia da input semantici di altre modalità come le mappe dei contorni. Tuttavia, gli attuali metodi T2I controllabili affrontano comunemente sfide legate all'efficienza e alla fedeltà, specialmente quando il condizionamento avviene su molteplici input provenienti dalla stessa modalità o da modalità diverse. In questo articolo proponiamo un nuovo metodo flessibile ed efficiente, FlexEControl, per la generazione T2I controllabile. Al centro di FlexEControl c'è una strategia unica di decomposizione dei pesi, che consente un'integrazione semplificata di vari tipi di input. Questo approccio non solo migliora la fedeltà dell'immagine generata al controllo, ma riduce anche significativamente il sovraccarico computazionale tipicamente associato al condizionamento multimodale. Il nostro approccio ottiene una riduzione del 41% dei parametri addestrabili e del 30% dell'utilizzo di memoria rispetto a Uni-ControlNet. Inoltre, raddoppia l'efficienza dei dati e può generare in modo flessibile immagini sotto la guida di molteplici condizioni di input di varie modalità.
citazione
@article{he2025flexecontrol,
title = {FlexEControl: Flexible and Efficient Multimodal Control for Text-to-Image Generation},
author = {He, Xuehai and Zheng, Jian and Fang, Jacob Zhiyuan and Piramuthu, Robinson and Bansal, Mohit and Ordonez, Vicente and Sigurdsson, Gunnar A and Peng, Nanyun and Wang, Xin Eric},
year = {2025},
journal = {Transactions of Machine Learning Research, TMLR 2025.},
url = {https://arxiv.org/abs/2405.04834},
}