Double-Hard Debias: Tailoring Word Embeddings for Gender Bias Mitigation
Résumé du communiqué de presse
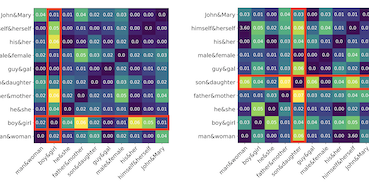
Des chercheurs de l'université de Virginie et de Salesforce Research ont identifié un facteur jusque-là négligé qui compromet les techniques courantes de suppression du biais de genre dans les plongements de mots — la fréquence statistique des mots dans les données d'entraînement. Les plongements de mots, ces représentations numériques du langage utilisées dans d'innombrables applications d'IA et de traitement du langage naturel, sont connus pour encoder des stéréotypes de genre de société, comme associer « programmeur » aux hommes et « personne au foyer » aux femmes. La solution dominante à ce problème, un algorithme appelé Hard Debias, fonctionne en identifiant puis en projetant hors de l'espace de plongement une « direction de genre », mais les chercheurs ont constaté que l'information de fréquence des mots incrustée dans les plongements déforme cette direction de genre avant qu'elle ne puisse être proprement supprimée. Pour remédier à cela, ils ont conçu une méthode en deux étapes appelée Double-Hard Debias, qui retire d'abord la composante liée à la fréquence des plongements puis applique la procédure Hard Debias standard. En testant les plongements GloVe et Word2Vec sur trois benchmarks de biais standard — comprenant une tâche de résolution de coréférence, un test d'association de mots et une vérification géométrique fondée sur le partitionnement — leur approche a réduit le biais de genre mesurable de manière plus substantielle que les méthodes précédentes, l'écart entre les performances d'un système de coréférence sur des phrases stéréotypées et contre-stéréotypées en matière de genre passant de 15,2 points de pourcentage avec GloVe non modifié à seulement 0,9 avec leur méthode, tout en préservant largement la qualité linguistique générale sur les tâches d'analogie et de catégorisation de mots. Ces travaux suggèrent que l'assainissement des plongements de mots exige de prêter une attention plus soutenue aux artefacts structurels que laissent derrière elles les statistiques de corpus.
résumé
Les plongements de mots dérivés de corpus générés par des humains héritent d'un fort biais de genre qui peut être encore amplifié par les modèles en aval. Certaines approches de débiaisement couramment adoptées, dont l'algorithme fondateur Hard Debias, appliquent des procédures de post-traitement qui projettent les plongements de mots pré-entraînés dans un sous-espace orthogonal à un sous-espace de genre inféré. Nous découvrons que des régularités du corpus indépendantes de la sémantique, telles que la fréquence des mots captée par les plongements, nuisent aux performances de ces algorithmes. Nous proposons une technique simple mais efficace, Double Hard Debias, qui purifie les plongements de mots vis-à-vis de telles régularités du corpus avant d'inférer et de supprimer le sous-espace de genre. Des expériences sur trois benchmarks d'atténuation des biais montrent que notre approche préserve la sémantique distributionnelle des plongements de mots pré-entraînés tout en réduisant le biais de genre dans une mesure nettement plus importante que les approches antérieures.
détails
citation
@inproceedings{wang2020double,
title = {Double-Hard Debias: Tailoring Word Embeddings for Gender Bias Mitigation},
author = {Wang, Tianlu and Lin, Xi Victoria and Rajani, Nazneen Fatema and McCann, Bryan and Ordonez, Vicente and Xiong, Caiming},
year = {2020},
booktitle = {Association for Computational Linguistics. ACL 2020},
url = {https://arxiv.org/abs/2005.00965},
}